数值计算
逻辑数组
逻辑数组的产生
用运算符 >、== 这样的,满足条件的位置为逻辑 1,不满足条件的位置为逻辑 0
以 is 开头的函数,可以进行一些类型的判断,比如isnan,判断每个元素是否为 nan
逻辑运算
符号 | 含义 |
|---|---|
& | 与 |
| | 或 |
~ | 非 |
xor(A, B) | 异或 |
all(A) | 是否全为非0 |
any(A) | 是否有0 |
与运算在 if 里面是 && 而在逻辑数组运算的时候是 & ,或运算也一样。
筛选数组
A = [1, 2, 3; 4, 5, 6];
B = A(A > 3);
C = A .* (A > 3);
D = A .* A > 3;
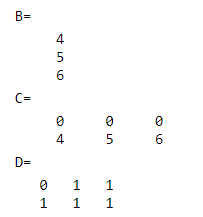
加点是对每个元素操作,不加点是对矩阵进行操作
B 是一个列向量,里面包含了大于 3 的所有值
C 是一个数组,里面小于等于 3 的值全部被置为 0
D 的运算顺序是先 .* 后 > 所以结果是逻辑数组
A = [1, 2, 3; 4, 5, 6; 7, 8, 9];
B = [1 0 1];
C = A(B == 1, :);
D = A(:, B == 1);

以上的代码是经常碰到的情况,A 是一个 m * n 的矩阵,B 是一个向量,现在要根据 B 条件筛选 A
可以看到,用切片的形式写逻辑向量,就会根据 B == 1 所代表的逻辑 1 筛选行和列。
无论 B 是行向量或是列向量都不影响,因为在切片里面,都化为了一维索引。
MATLAB 随机数产生
rand(size1,size2, ... ,sizeN)
产生 0~1 随机数,size 指定产生矩阵的维度。
rand(3,4) 产生 3 × 4 的随机矩阵
randn(size1,size2, ... ,sizeN)
产生标准正态分布随机数,size 指定矩阵维度。
randi([imin,imax], size1,size2, ... sizeN)
产生 imin 和 imax 之间的整数,包含 imin 和 imax
如果省略 imin 则生成 0 到 imax 之间整数
randi(5,2,3) 则产生 1 到 5 的之间的随机数,生成一个 2 × 3 矩阵
randperm(n,k)
产生一个行向量,其中包含在 1 到 n(包括二者)之间随机选择的 k 个唯一整数,其顺序也是随机的。
若省略 k ,则返回行向量,其中包含从 1 到 n(包括二者)之间的整数随机置换。
MATLAB 概率统计
均值
函数 | 说明 |
|---|---|
M=mean(A) | 计算矩阵A平均值 |
M=mean(A, dim) | 计算指定维度上向量的平均值 |
nanmean | 算术平均值 |
geomean | 几何平均值 |
harmmean | 和谐平均值 |
trimmean | 调整平均值 |
方差与标准差
函数 | 说明 |
|---|---|
V=var(X) | 计算方差(n-1标准化) |
V=var(X,1) | 计算二阶中心距(n标准化) |
V=var(X,w) | w为权重向量 |
V=var(X,w,dim) | dim规定计算的维度 |
std | 计算上述对应的算术平均值 |
方差和二阶中心距:
S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i- \bar{X})^2 \quad \quad
\tilde{S}^2 = \frac{1}{n} \sum_{i=1}^n (X_i- \bar{X})^2
协方差
函数 | 说明 |
|---|---|
cov(x) | x为向量时计算方差,x为矩阵时计算协方差矩阵 |
cov(x,y) | 计算x、y的协方差矩阵 |
cov(x,1) | 使用n标准化 |
cov(x,y,1) | 使用n标准化 |
相关系数
函数 | 说明 |
|---|---|
R=corrcoef(X) | 计算矩阵X列向量元素相关系数矩阵 |
R=corrcoef(x,y) | 计算列向量x、y的相关系数矩阵 |
[R,P]=corrcoef(...) | P返回的是不相关的概率矩阵 |
[R,P,PLO,PUR]=corrcoef(...) | RLO、RUP是95%置信度的估计区间上、下限 |
常见分布的随机数的产生
函数 | 随机数名 |
|---|---|
unifrnd | 连续均匀分布 |
unidrnd | 离散均匀分布 |
exprnd | 指数分布 |
normrnd | 正态分布 |
chi2rnd | 卡方分布 |
trnd | t分布 |
Frnd | F分布 |
gamrnd | γ分布 |
betarnd | β分布 |
lognrnd | 对数正态分布 |
nbinrnd | 负二项式分布 |
ncfrnd | 非中心 F 分布 |
nctrnd | 非中心 t 分布 |
ncx2rnd | 非中心卡方分布 |
raylrnd | 瑞利分布 |
weibrnd | 韦伯分布 |
binornd | 二项分布 |
geornd | 几何分布 |
hygernd | 超几何分布 |
poissrnd | 泊松分布 |
参数表前面是各分布的参数,后面的m、n是产生随机数的行列数
n = 10:10:60
% 求六个随机数,每个随机数参数由 n 向量决定
r1 = binornd(n, 1./n)
% 产生两行四列的随机数,随机数参数是10和0.1
r2 = binornd(10, 1/10, [2,4])
概率密度的计算
y = pdf(name, X, A)
name取值1 | name取值2 | 分布 |
|---|---|---|
beta | Beta | β |
bino | Binomial | 二项 |
chi2 | Chisquare | 卡方 |
exp | Exponential | 指数 |
f | F | F |
gam | Gamma | γ |
geo | Geometric | 几何 |
hyge | Hypergeometric | 超几何 |
logn | Lognormal | 对数正态 |
nbin | Negative Binomial | 负二项式 |
ncf | Noncentral F | 非中心F |
nct | Noncentral t | 非中心t |
ncx2 | Noncentral Chi-square | 非中心卡方 |
norm | Normal | 正态 |
poiss | Poisson | 泊松 |
rayl | Rayleigh | 瑞利 |
t | T | t |
unif | Uniform | 均匀 |
unid | Discrete Uniform | 离散均匀 |
weib | Weibull | 韦伯 |
其中 X 表示数据点,A表示分布的参数
上述特殊分布的概率密度可以同等价的函数,如F分布可以用 fpdf( )
任意函数的概率密度可用函数 ksdensity
% 表示在 x = 6 处,分布参数为 7,8 的概率密度
y = pdf('F',6, 7, 8)
% 计算 x = 5 和 x = 6 的概率密度
y = pdf('F', [5 6], 7, 8)
% 计算参数为 7,8 和 9,10 的概率密度
y = pdf('F', 6, [7, 9], [8, 10])
y = fpdf(6, 7, 8)
累积概率值
将概率密度计算的函数 pdf 改为 cdf 即计算累积概率值。
补充一些函数
sort
sort(A,dim)
对 A 中元素按一定顺序进行排列,默认 dim = 1,对每一列排序。
注意 sort 会对每一列的数据进行排序,会破坏同一行之间的对应关系
[B,I] = sort(A,dim)
返回的 B 为对应排序后的矩阵,返回的矩阵 I 的第 i 行表示排序后的第 i 行是原矩阵 A 的第 I(i) 行。
要对矩阵 A 根据第一列排序,应用如下代码进行:
A = [1 5 6;5 9 4;3 5 7;6 8 2];
[B,I] = sort(A(:,1));
C = zeros(4,3);
for i = 1:4
C(i,:) = A(I(i),:);
end
disp(A);
disp(C);

find
k = find(X,n)
返回矩阵 X 中前 n 个非零元素的索引
若省去 n 则返回所有非零元素索引
若要查询等于 a 的位置,可以用 X == a 表示,同样查询小于 a 的位置可以用 X < a 表示
[row, col] = find(X,n)
返回矩阵 X 中满足要求的横坐标和纵坐标
如果仅仅要得到矩阵中满足要求的元素,可以用以下的逻辑形式改善性能
clear
A = [1 5 6;5 9 4;3 5 7;6 8 2];
L = A <= 4
B = A(A <= 4)
C = A.*(A <= 4)
gscatter
gscatter(x,y,g,color,marker,size)
以 x 为x轴,y 为y轴,根据 g 的对应分类情况作散点图
g 必须和 x、y相同维度,可以是数字表示,也可以是分类变量
color 表示颜色,marker 是符号,size 是大小
load discrim
gscatter(ratings(:,1),ratings(:,2),group,'br','xo')
xlabel('climate')
ylabel('housing')
xtickangle(ax,angle)
将 x 轴刻度选择 angle 角度。
当 x 轴数据长度过长时,会出现重叠情况,将其旋转一定角度可以避免重叠
xtick(ax,format)
将 x 轴刻度按规定显示

[trainInd,valInd,testInd] = dividerand(Q,trainRatio,valRatio,testRatio)
在神经网络等算法中,需要划分数据为三份:train(训练数据)、validate(验证数据)、test(测试数据),本函数可以方便随机划分为三类
Q 是正整数,是样本总数量
后三个参数是三类所占百分比,在 0~1 之间,默认值为0.7, 0.15, 0.15
得到的是三组数据的序号行向量。
MATLAB 函数与主工作区间数据交流
## assignin(ws,var,val)
ws 有两种情况,‘base’ 或 ‘caller’,其中 ‘base’ 表示基础工作区,‘caller’ 在函数嵌套中使用,主函数调用子函数,‘caller’表示主函数区。
ws 为 ‘base’ 时,表示将 val 赋值给基础工作区的变量 var。
assignin('base','name',n);
不会为数组的特定元素赋值,下面的代码会出错。
assignin('base','X(3:5)',-1); % 错误
[a1, a2, a3, ...] = evalin(ws, expression)
执行 expression,它是一个字符向量或字符串标量,包含任何有效的 MATLAB 表达式,这些表达式使用工作区 ws 中的变量。
可以用这个函数将基础工作区的变量赋值到局部函数区
v = evalin('base', 'var');
将变量 var 赋给 v
MATLAB 表的使用和查询
拿到的数据是 table 的形式,我们需要知道一些基本的方法,把 table 转换为我们熟悉的数组。
tableName.Properties.VariableNames
tableName为表的名称,返回一个 Cell,Cell 中为表中每个属性的名称。
tableName.PropertyName
PropertyName 为表中某个属性名称,如果这个属性是数字,则返回一个数组,否则返回元胞数组。
table2array(tableName)
返回一个数组,里面包含表中的数字数据。
varfun(func,T)
对表 T 中每一个元素进行 func 例如:
varfun(@double,T):化为小数
varfun(@mean,T):求均值
varfun(func,T,Name,Value)
设置一组属性值,如 ‘OutputFormat’ 指定输出格式。
tabulate(T)
统计信息
高级数据结构——table
构造 table 对象
构造函数
T = table(var1,...,varN)
根据变量名 var 构造表,所有变量的行数必须相同
T = table('Size',sz,'VariableTypes',varTypes)
为表格创建空间,sz 为行向量,指定维数,例如【4,3】表示 4 行 3 列;varTypes为数据类型元胞数组。
sz = [4 3]; varTypes = {'double','datetime','string'}; T = table('Size',sz,'VariableTypes',varTypes)
- ##### T = table(___,'VariableNames',varNames) - 指定输出表中的变量的名称,即每一列的名称;第四种添加每一行的名称。 - ##### T = table(___,'RowNames',rowNames) ```matlab
T = table(categorical({'M';'F';'M'}),[45;32;34],logical([1;0;0]),... 'VariableNames',{'Gender','Age','Vote'},... 'RowNames',{'NY';'CA';'MA'})
- ##### T = table
- 建立空 table 对象
## 通过转换构建表
- 可以通过 array2table、cell2table、struct2table 等构造表
- 区分table与array2table
```matlab
a = [1 2 3;4 5 6]
A = table(a)
B = array2table(a)
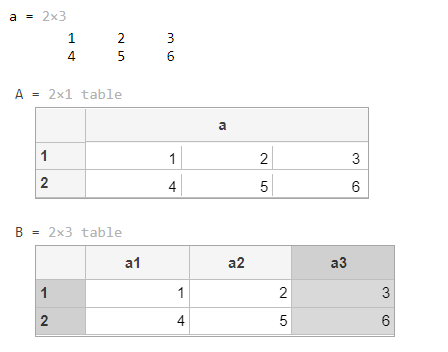
struct2table用法
S.Name = {'CLARK';'BROWN';'MARTIN'}; S.Gender = {'M';'F';'M'}; S.SystolicBP = [124;122;130]; S.DiastolicBP = [93;80;92]; struct2table(S)访问table中的数据
使用 Dot + VariableNames 可以返回指定名称的列,返回的是一个 Cell 数组
可以和数组一样使用 ()访问,返回的依旧是 table,如果是 {} 则返回 Cell 数组
对table的操作
删除行列
T(3,:) = [];
添加行列
T.name1 = {'var1';'var2';'var3'};
合并table
t1 = [1 2 3;4 5 6]
table(t1)
t2 = [7 8 9;3 5 7]
table(t2)
T1 = [t1;t2]
T2 = [t1,t2]

如果是;连接两个表格,则是行数变多,列数不变
如果是,连接两个表格,则是行数不变,列数增多
对table进行排序
sortrows函数
筛选和查找
利用逻辑运算筛选
T1 = T(T.name1 > 200,:);
T2 = T( (T.name2 > 200) & (T.name3 > 200),: );
T3 = T(strcmp(T.name4,'name'),:);
函数部分
定义函数
要求文件名与函数名相同
function [a, b] = functionName(c, d)
end
输出一个
eg:在名为average.m的文件中定义一个函数,该函数接受输入向量,计算值的平均值,并返回单个结果
function ave = average(x)
ave = sum(x(:))/numel(x);
end
z = 1:99;
ave = average(z)
输出:
输出多个
eg:在名为stat.m的文件中定义一个函数,该函数返回输入向量的平均值和标准偏差。
function [m,s] = stat(x)
n = length(x);
m = sum(x)/n;
s = sqrt(sum((x-m).^2/n));
end
%从命令行调用函数
values = [12.7, 45.4, 98.9, 26.6, 53.1];
[ave,stdev] = stat(values)
输出:
一个文件中多个函数
定义一个函数,将输入限制为不包含Inf或NaN元素的数字向量。此函数使用arguments关键字
function [m,s] = stat3(x)
arguments
x (1,:) {mustBeNumeric, mustBeFinite}
end
n = length(x);
m = avg(x,n);
s = sqrt(sum((x-m).^2/n));
end
function m = avg(x,n)
m = sum(x)/n;
end
间接使用函数
用@引用函数后可以间接使用函数
h = @cos;
h(pi);
这里 h(pi)就相当于 cos(pi),因为 h 引用了 cos 函数的句柄。
更常见的情况是将引用的句柄当做函数的参数传入另一个函数(主函数),这样在主函数中,我们就可以根据输入调用不同的函数。例如:
% main.m
function test(functionHandle)
a = functionHandle(pi/4);
disp(a)
end
% 命令行
test(@sin);
test(@tan);
会输出 0.71 和 1
匿名函数
可以用 @ 构造简单的匿名函数,例如:
h = @(x) x^2 + sin(x);
这样其实相当于建立了一个函数文件,将其句柄赋给了 h,但是并没有真实存在的 m 文件,而是直接用 h 表示了。
将其理解成一个函数 m 文件,就很好理解 h 可以直接计算函数值,例如 h(4);但是并不能进行符号运算,例如 h + h 就会报错。
这是属于 MATLAB 符号运算的知识,各种符号函数的区别,移步符号函数。
函数重载
在 MATLAB 中,函数重载不能像 C++ 一样通过不同的参数类型进行重载,而要在函数体内实现。
简单的说就是 “伪重载”,用 if 判断,当输入为什么时怎么样。
函数体内有几个系统自动设定的变量,帮助我们完成重载。
nargin
nargin 为调用函数时输入的参数个数
在 MATLAB 中,不需要定义时的参数与调用时的参数个数相同,即定义参数(x,y)但是调用时可以只输入参数 x
特别注意在类的方法中,obj 参数虽然在调用时并不用写,但是也算一个参数(这是面向对象的知识,小白可以无视)
varargin
输入的参数可以只用一个 varargin 表示,然后调用时输入的参数都在这个 varargin 元胞数组中,用 varargin{1} 即可获得第一个输入参数
注意在类的方法中,如果用 对象名.方法名(参数) 调用,varargin 第一个参数是这个对象而不是我们输入的第一个参数。
classdef Point2D < handle
properties
x;
y;
end
methods
function obj = Point2D(x0,y0)
obj.x = x0;
obj.y = y0;
end
function moveTo(varargin)
disp(varargin)
disp(varargin{1})
end
end
end
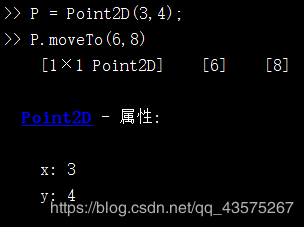
varargin 可以出现在已有参数的末尾,例如上面这个例子,在类的方法中我们肯定会用到 obj 这个参数,所以我们可以将其单独拿出来。
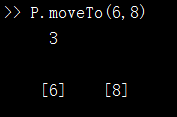
function moveTo(obj,varargin)
if nargin == 1
obj.x = 0;
obj.y = 0;
elseif nargin == 2
obj.x = varargin{1};
obj.y = 0;
elseif nargin == 3
obj.x = varargin{1};
obj.y = varargin{2};
end
disp(nargin)
disp(varargin)
end
nargout、varargout
同理,nargout 表示输出的参数个数,varargout 表示输出,用于重载输出。
矩阵基础操作
矩阵创建、切片、修改、删除
创建
% 逗号或空格表示同一行的数,分号表示不同行
A = [1, 2, 3; 4 5 6];
% 分号表示 起始:间距:终值
A = 1:3; %[1 2 3]
A = 1:2:5; %[1 3 5]
% linspace函数,参数分别为起始值、中值、取点数量。等距离取点,得到等差数组
A = linspace(0, pi, 100);
除了上述常用方法,还有下面的特殊函数:
命令 | 说明 | 命令 | 说明 |
|---|---|---|---|
eye(n) | n×n单位阵 | eye(m,n) | m×n单位阵 |
ones(n) | n×n全1矩阵 | ones(m,n) | m×n全1矩阵 |
zeros(n) | n×n全0矩阵 | zeros(m,n) | m×n全0矩阵 |
rand(n) | n×n随机矩阵 | rand(m,n) | m×n随机矩阵 |
diag(v) | v为对角元素创建方阵 | diag(v,k) | v为第k条对角线创建矩阵 |
切片
% 第 1 行第 2 列
A(1, 2)
% 第 2 行所有列
A(2, :)
% 倒数第二行,第 1、3、5列
A(end-1, [1 3 5])
修改
对切片进行复制可以修改,但是两边矩阵的大小要一模一样。
A([2, 4, 6], [1, 3]) = [8, 6; 5, 7; 5, 4];
删除
直接对切片赋 [],即可删除。
矩阵相关函数
以下总结了常用的矩阵相关函数,简单来说,所有你能想到的基本操作都有对应的函数,想干什么直接 google 以下,找都函数名就行了。
命令 | 说明 |
|---|---|
rot90(A) | 将A逆时针旋转90° |
rot90(A,k) | 将A逆时针旋转k×90° |
flipdim(X,dim) | dim=1时上下翻转,dim=2时左右翻转 |
det(A) | 求矩阵行列式 |
eig(A) | 求矩阵特征值 |
inv(A) | 求矩阵的逆 |
rank(A) | 求矩阵的秩 |
trace(A) | 求矩阵的迹 |
矩阵运算
A = [1, 2, 3; 4, 5, 6];
% 每个元素都加 1
B = A + 1
% 对应元素分别相加
B = A + [7, 8, 9; 10, 11, 12];
% 第一行加 1,第二行加 2
B = A + [1; 2];
%第一列加 1,第二列加 2,第三列加 3
B = A + [1, 2, 3];
矩阵的乘法,就要注意了, * ^ / \ 对应的是矩阵的乘除运算,在前面加一个 . 才表示对应位置的数据分别相乘、相除。
A/B 表示 ,A\B 表示 ,而 A./B 和 A.\B 就没区别了。
A = [1, 2; 3, 4];
B = [3, 4; 5, 6];
% 矩阵乘法
C = A * B;
% 对应位置相乘
C = A .* B;
向量与多项式
一个向量可以代表一个多项式,例如 [3 -2 1 0 5] 可以对应多项式:
3x^4-2x^3+x^2+5
所以可以直接用向量调用下面的函数就可以进行多项式运算:
conv(p1,p2)
求p1和p2对应多项式的乘积。
[k,r]=deconv(p,q)
k返回的是多项式p除以q的商,r是余式。即
polyder(p)
求对应多项式导数的向量。
sym2poly(f)
将多项式函数化为向量。其中 f 是数学符号表达式。
本文章使用limfx的vscode插件快速发布