K-means聚类分析
K聚类用法
-
事先定义K,将数据分为K组,把相似数据并成一组。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。最后得出每个样本属于哪一类以及各类的中心点
-
优点: 算法原理简单,处理快。当聚类密集时,类与类之间区别明显,效果好
-
缺点:
- K是事先给定的,K值选定难确定
- 对孤立点、噪声敏感
- 结果不一定是全局最优,只能保证局部最优。
- 很难发现大小差别很大的簇及进行增量计算
- 结果不稳定,初始值选定对结果有一定的影响,且计算量大
[idx,C,sumd,D] = kmeans(X,K)
-
输入 X 是要分类的数据矩阵,每一行是一个样本,每一列是一组特征值。输入 K 是规定的分类组数。
-
idx 是一个列向量,记录对应位置处样本所属类的序号。
-
C 记录了 K 个类的中心点的坐标。
-
sumd 记录了每组的中心点,每一行是一个中心点坐标。
-
D 记录了每个点到每个中心点的距离的平方,第 i 行的第 j 列为第 i 个样本到第 j 组中心点的距离平方。
K值确定
-
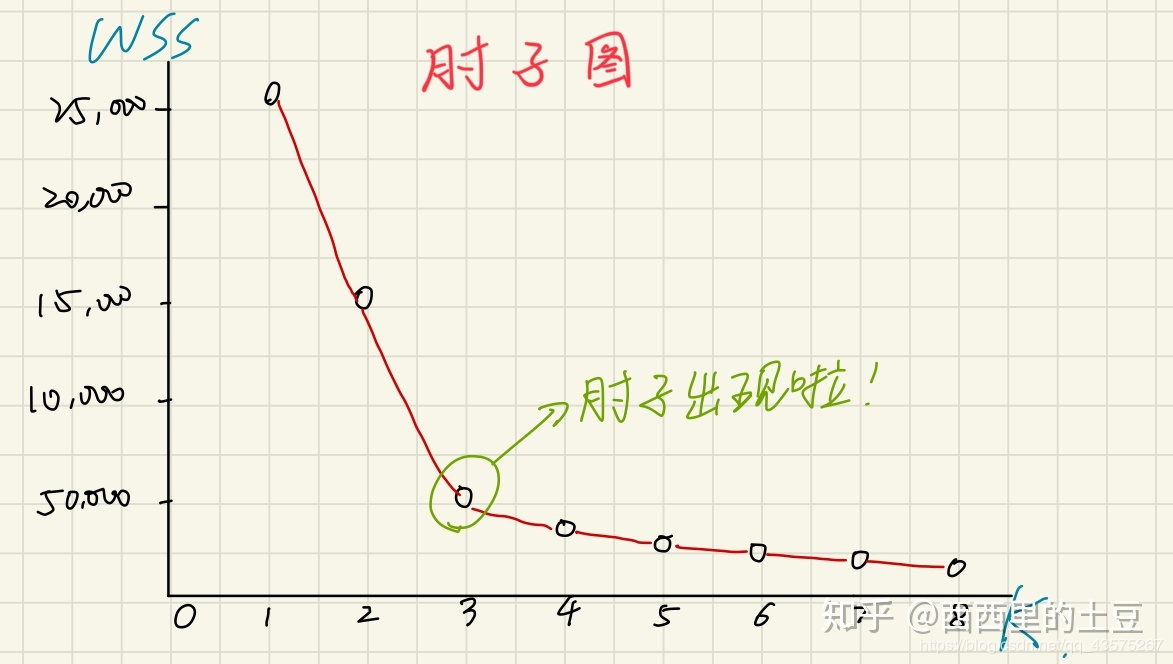
随着 K 值的增大,所有点到其所对应的中心点距离的平方(WSS)会减小(由于算法原因,每一次运行结果可能有所波动),当 K 增大到所有点的个数时,每个点自成一类,WSS变为0。所以,做出X轴是K值,Y轴是WSS的图,看到那个拐弯处最厉害的地方就是理想的 K 值,因为再增加 K 也不会很大地改善分类效果了。
-
肘子图
实例
X = [0 0;1 0; 0 1; 1 1;2 1;1 2; 2 2;3 2; 6 6; 7 6; ...
8 6; 6 7; 7 7; 8 7; 9 7 ; 7 8; 8 8; 9 8; 8 9 ; 9 9];
[idx,C,sumd,D] = kmeans(X,2);
figure
plot(X(:,1),X(:,2),'b*','MarkerSize',10);
hold on
plot(C(:,1),C(:,2),'ro','MarkerSize',10);

本文章使用limfx的vscode插件快速发布