Oracle学习总结
sys可以匿名登录的原因
sys 匿名登录:conn / as sysdba
oracle 三种登录验证机制
- 操作系统验证
- 密码文件严重
- 数据库验证
一般权限用户都是第三种验证,因为用户名和密码都是存储在数据库当中的。 sys用户默认验证方式是一,操作系统验证,当操作系统用户名删除后就会用密码文件方式验证=
数据
- 数据是数据库种存储的基本对象
- 数据是描述事物的符号记录
- 数据与其语义是不可分的
数据库和信息的关系
数据是信息的载体,他是信息的具体表现形式,信息是各种数据所包括的意义。
数据库是长期存储在计算机内,有组织、可共享的大量数据集合。
数据库管理系统(database management system ,DBMS)是位于用户与操作系统之间的一层数据管理软件 dbms的用途:科学地组织和存储数据、高效地获取和维护数据。
DBMS的主要功能
- 数据定义DDL
- 数据操纵DML:插入、删除、修改
- 数据库运行管理功能
数据库系统DBS,database system 是指在计算机系统种引入数据库后的系统构成,数据库系统称数据库
数据库是在计算机系统中按照一定的数据模型组织、存储和应用的数据的集合,支持数据库各种操作的软件系统叫数据库管理系统,由计算机、操作系统、DBMS、数据库、用用程序和用户等组成的一个整体叫做数据库系统。
数据模型
- 概念模型:对现实世界的第一级抽象:E-R模型
- 逻辑模型和物理模型:第二级抽象,主要包括网状模型、层次模型、关系模型、面向对象模型
现实世界中的客观对象抽象为概念模型,把概念模型转换为某一数据库管理系统支持的数据模型
概念模型转逻辑结构
即E-R图转关系模型 转换原则:
- 实体必须转换为一个关系模式,用下划线表示关系模式的健码
- 实体间的联系的转换规则:
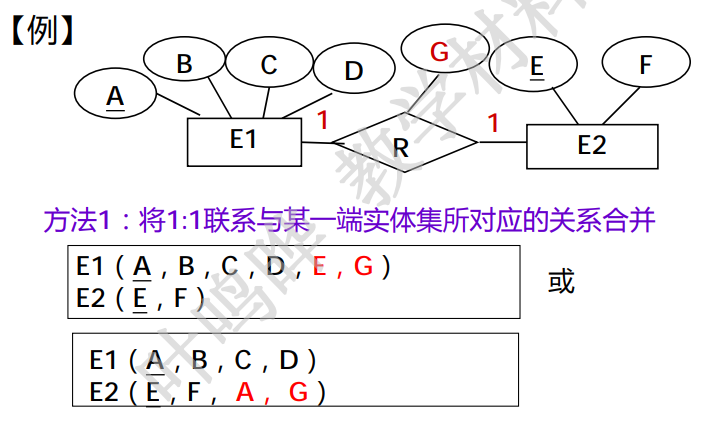
- 一对一关系可以与任意一端对应的关系模式合并,在需要被合并关系中增加属性,其新增属性为联系本身的属性和与联系相关的另一个实体的主键。
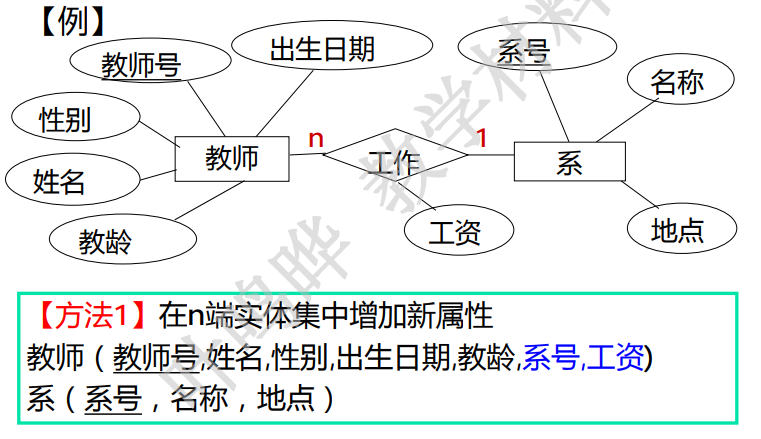
- 一对多关系,修改多端,在多端实体集中增加新属性,新属性由一端实体集的主键和联系本身的属性构成,新增属性后原关系主键不变
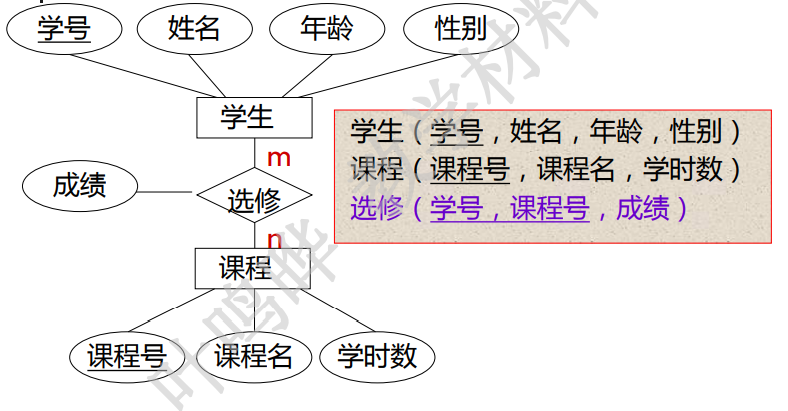
- 多对多转换为一个独立关系模式,新关系的主键为两个相连实体的主键的组合
- 一对一关系可以与任意一端对应的关系模式合并,在需要被合并关系中增加属性,其新增属性为联系本身的属性和与联系相关的另一个实体的主键。
- 具有相同码的关系模式可以合并
sql*plus
退出sqlplus的两种方式
- 单击窗口的关闭按钮:Oracle认为没有正常退出,不会在退出前执行提交操作,因此可能导致未提交事物的自动回退
- 执行exit或quit命令:执行提交操作
sys用户
sys的权限比system的大 数据库中数据字典的拥有者,是Oracle权限最高的用户,必须用sysdba进行连接,即conn sys/password as sysdba
system用户可以不适用sysdba进行连接,system可以拥有普通dba角色权限
数据库用户
授权语句 grant sysdba to 用户名 收回权限语句 revoke sysdba from用户名
对scott用户解锁
alter user scott identidied by tiger account unlock
sql*plus常用命令
sql*plus命令的结尾处可以不使用分号
| 命令 | 作用 | 格式 | 其他 |
|---|---|---|---|
| help | 查看某个命令的使用方法 | help[topic] | help index 查看所有的命令清单 |
| connect | 以某个用户身份连接到某个数据库 | conn[ect] 用户名/密码@sid | 当特权用户身份连接时,语句末尾必须带上as sysdba |
| disconnect | 用来断开与当前数据库的连接 | disc[onnect] | 在sql>下输入disc即可 |
| password | 用于修改当前用户的密码,或某个用户密码 | 当前密码修改:passw[ord];某个用户密码修改:passw[ord] 用户名 | 若修改其他用户的密码,需要用sys或system登录 |
| show | 由于显示当前系统变量和环境变量 | show user 查看当前会话连接用户 | show parameter db_name,当以dba身份登录时,查看当前连接到哪个数据库 |
| describe | 用来查看数据对象的结构 | desc[ribe] 对象名 | desc scott.emp 查看scott用户中的emp表的结构 |
| linesize | 设置显示行的宽度,默认80个字符 | set linesize 90 设置行的宽度 | show linesize 显示行的宽度 |
| pagesize | 设置每页显示的行数目,默认14 | 与上类似 | 与上类似 |
| edit | 可以编辑指定的文件(记事本打开) | ed[it] 文件路径 | ed e:\a.sql,如果没有文件路径,打开的是缓冲区 |
| run | 运行缓冲区中的sql语句 | r[un] | 等价于/ |
| &替代变量符号 | 表示该变量是替代变量,在执行时,需要用户输入 | & 变量名 | SELECT * FROM emp WHERE job='&job'; |
| list | 显示缓冲区中的内容 | l[ist] | SQL> L --显示SQL缓冲区内容 |
| n text | 将缓冲区中的语句的第n行内容替换成文本text | n text | SQL> 2 FROM emp --将缓冲区中的第二行换成 FROM emp |
| n | 设置当前行为第n行 | SQL> 1 --设置第一行为当前行 | |
| append | 将文本text附加到当前行的末尾 | a[ppend] text | SQL> A ,job,sal --在当前行末尾添加”,job,sal”内容 |
| del | 删除缓冲区中第n行 | del n | SQL> DEL 4 --将缓冲区中的第4行删除 |
| change | 将缓冲区当前行用“新的正文”替代“原文” | c[hange]/原文/新的正文 | SQL> C /DEPT/EMP --将当前行的dept改为emp |
| save | 把当前缓冲区中的内容保存到指定文件 | save 文件路径 | SQL> SAVE d:\b.sql --把当前缓冲区中的内容保存到d:\b.sql |
| get | 将指定文件的内容加载到缓冲区中,并显示该文件的内容 | get 文件路径 | SQL> GET d:\b.sql --把d:\b.sql 文件内容加载到当前缓冲区中 |
| start或者@ | 执行sql脚本文件命令 | start 文件名 | SQL> START d:\b.sql --将d:\b.sql 文件内容加载到当前SQL缓冲区中,并运行。等价于SQL> @文件名 |
| spool | 将sqlplus屏幕上的内容包括执行的命令及其结果,输出到指定文件中去。 | spool d:\b.sql (此句在 sql操作语句之前加入)直到输入spool off为止 |
控制sqlplus环境
控制环境的两个命令:show、set
show 查看环境变量,查看所有SET变量值,可以使用SHOW ALL命令
set 设置环境变量,从而控制环境,set 环境变量 变量的值
echo 默认值为off,若在脚本文件中echo值为on时,运行脚本不但放回查询结果,还返回查询语句,改变echo命令:set echo on
feedback,改变feedback命令语句:SET FEED[BACK] {6|n|OFF|ON},其中n为自然数,6为Oracle的默认值。设置feeback是为了子查询时,如果查询选择的数据行数大于n时,显示返回的数据行数。如果小于n时,就不显示返回的记录数。
set hea[ding]{on|off}是否显示列的标题
colunm格式化|命令
col[umn][{列名|别名}] 可选项格式为cle[ar]|for[mat]格式化模式|hea[ding]正文…… column loc clear --清楚loc列的所有格式 column loc --查看loc列所有的格式 format的格式元素:
- an:为varchar类型的列的列内容设置宽度,如果内容超过指定的宽度,则自动换行,如A10
- 9:设置number列的显示格式,如999 9999
- 99
- L:本地的货币符号,如L99
- .:小数点位置,如9999.9
- ,:千分位分隔符,如9,999
第四章,sql语句基础
select 列名 [*,算术表达式,聚集函数] from 表明 where 查找条件 group by 基于分组的列名 having 分组条件 order by 居于排序的列名 ps select语句的执行过程:from-->where-->group by-->having-->select-->order by
select语句
基本查询
- 定义列的别名
- 列名和别名之间使用空格间隔或者使用关键字as
- 如果别名包含空格或特殊字符,或区分大小写使用双引号,如select empno "empNo"
- 连接操作符
格式:列名||列名(其中||为连接操作符),用于连接列与列、列与算术表达式或与常量之间创建一个字符表达式,连接符两边的列将组合成一个列作为结果输出
例如
select ename||job as "Employees" from emp;--emp表中的ename和job列合并成为Employees列
条件查询
- 字符串和日期型数值都要用单引号引起来 字符型数值区分大小写,日期型数值区分日期表达形式,默认日期为DD-MON-YY
- 比较操作符:=;<;>;>=;<=;!=等同于<>,意为不等于
- between……and……,两个值之间,包含
- in(…,…,…,…)和多个值任何一个匹配
- like 字符串匹配
- %表示零或任意更多的字符
- _表示一个字符
- escape转义字符
搜索以“QA_”开头的数据
select CODE from CNT_CODELIST where code like 'QA/_%'escape '/'
- is null是空值 空值意味着这个值是不可用的、未分配的、未知的和不可应用的。空值不能等于或不等于任何值,因此不能用等号来测试。
- 优先规则(从高到低):所有比较运算符>not>and>or
使用括号可以改变优先权
分组查询
-
group by 子句
- 使用group by子句将查询结果按by后面的列进行分组,列值相等的为一组

- 使用group by子句将查询结果按by后面的列进行分组,列值相等的为一组
-
having 子句
- 如果分组后还要求按一定条件对这些组进行筛选,最终只输出满足指定条件的组
- 作用:去掉不满足条件的组
在雇员表中,求部门员工数超过5个人的部门号和部门人数
select deotno,count(*) from emp group by deptno having count(*)>5; -
注意:
- 有group by才有having
- 若用到group by,投影的列只能是分组依据的列或是聚集函数列,聚集函数有avg;min;max;sum;count,其中sum和avg只接受数值类型
- count(*)和count(属性名)区别 *返回满足条件的元组的总个数,元组属性值为null也包括 属性名 返回该属性下取值不为null的总个数
- 聚集函数在输入为空集的情况下放回null,count函数输入空值返回0
- group by后面的列名可以不在select列表中
- group by后面的列名不可用别名
查询每个部门中有获得奖金的雇员人数,要求只显示获得奖金人数超过或包含3人的部门号和有获得奖金的雇员人数。
select deptno,count(comm)
from emp
where comm>0
group by deptno
having count(comm)>=3;
排序数据
asc 升序,默认
desc 降序
- order by后可用列的别名
- 多列参与排序
- order by列表的顺序就是数据排列的顺序
- 可以用没有在select列表出现的列进行排序
- 排序中null值的处理
- 在升序中,null排最后
- 降序中,null排最前
- order by 子句的末尾可以使用nulls first或nulls last指定空值显示在最开始或是最末尾
- 排序和rownum一起使用时
rownum表示行号,主要用于取前几条记录
语句1 查询emp表中按empno降序排列的前三个记录
语句2 取emp表中按工资降序排列前三条记录Select * from emp where rownum<=3 order by empno desc
总结:order by索引列(如主键),可以先按该字段排序,然后执行where,用rownum标号取前几行; order by普通列:先执行where,用rownum取前几行,后order by排序Select * from emp Where rownum<=3 order by sal desc
在雇员表中,查询每个部门中有多少员工的工资在1000到2500之间,查询结果按照员工人数降序排列。
select count(empno),deptno
from emp
where sal between 1000 and 2500
group by deptno;
函数
dual是一个虚拟表 只包含一个列dummy
单行函数格式:函数名[(参数1,参数2…)]
ps 单行函数只对表中的一行数据进行操作,并且对每一行数据只产生一个输出结果
单行函数可以用在select,where,order by子句中,可以嵌套
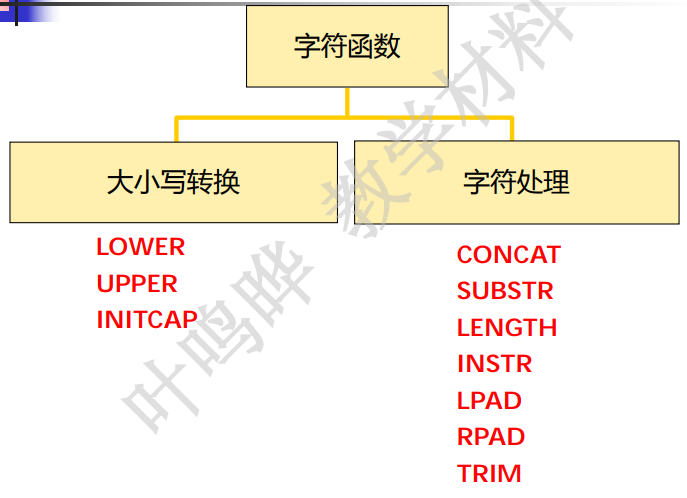
- 大小写转换函数
- lower('字符串'):将大小写混合字符串统一转小写
- upper('字符串'):将大小写混合字符串统一转大写
- initcap('字符串'):将每个单词的第一个字母转大写,其余转小写
- 字符处理函数
- concat('goood','string'):在good后追加string
- length('string'):求字符串string长度
- lpad(5000,10),'*'):在5000左边填充星号,使之长度为10
- rpad(5000,10),'*'):在5000右边填充星号,使之长度为10
- substr(列名|表达式,m[,n])
- 表示返回指定的子串,该串是从第m个字符开始的n个字符
- 若没有n值,则表示从第m个字符开始截取后面所有的字符串
- 注意
- 当m等于0或1时,都是从第一位开始截取
- 当m为负数时,表示从倒数的位置开始取字符。只要|m|<=n,取m的个数;当|m|>=n时,才取n的个数,由m决定截取位置
select substr('HelloWorld',-1,3) value from dual; --返回r,因为|m|<n所以取m个 select substr('HelloWorld',-4,3) value from dual; --返回orl,|m|>n,取n个 select substr('HelloWorld',-3) value from dual; --返回rld
- instr(列名|表达式,'字符串'[,m][,n])
- 表示返回所给字符串的位置,若找不到返回0
- m表示从第m个字符开始搜素,n表示所给字符串出现的次数,m和n默认为1
- 若m为负数,则表示倒数的位置开始,往回找
select instr('hellword','l',-2,3) from dual; --在字符串hellword中从倒数第二位置开始查找l,返回第三个l的位置,返回3select * from emp where instr(ename,'LA')>0; select * from emp where ename like '%LA%'; --作用一样- trim(leading '要去掉的字符'from '源字符串')
- 从源字符串中的头部尾部去掉要去掉的字符,默认both首尾都去掉
select trim(leading'h' from 'hhhahhhh') from dual;- replace(正文表达式,要搜寻的字符串,替换字符串)
- 从正文表达式中找到要搜寻的字符串,替换成替换字符串
select ename,concat(ename,job),--查找ename,连接ename,job为新列
length(ename),instr(ename,'A')--ename的长度,列ename中A的位置
from emp
where substr(job,1,5)='SALES';--job列从第一个字母开始正数5个字符串=‘SALES’
用字符函数实现查询姓名以N结尾的雇员(不能用like)
select * from emp
where substr(ename,'-1')='N';
--where instr(ename,'N',-1,1)=length(ename);
-
数值函数
函数 作用 其他 ceil(x) 返回大于或等于x的最小整数 ceil(6.6)-->返回7 power(x,y) 返回x的y次幂 power(2,3)-->返回8 round(x,[y]) 四舍五入到指定的小数y位,y为负数表示小数前 round(45.926,2)-->45.93;round(45.923,-1)-->50 trunc(x,[y]) 截取到指定的小数y位,y为负数表示小数前 trunc(45.926,2)-->45.92;trunc(45.923,-1)-->40 mod(x,y) 取余数 mod(7,3)-->1 -
日期处理
- 日期运算
| 操作 | 结果 | 描述 |
|---|---|---|
| 日期+-数字 | 日期 | 在日期的基础上加上或减去一定天数 |
| 日期-日期 | 天数 | 两个日期相隔的天数 |
| 日期+数字/24 | 日期 | 在日期的基础上加上一定的小时数 |
select ename,(sysdate-hiredate)/7 weeks
from emp;
where deptno=10;
--查询部门号为10的员工姓名以及到现在工作的周数
- 日期函数
- 只适用于Oracle
- 返回类型都为日期型,除了months_between,返回数值型数据
| 函数 | 描述 | 说明 |
|---|---|---|
| months_between(x,y) | 两个日期之间间隔多少个月 | 结果可正可负,非整数部分表示不足一个月 |
| add_months(x,y) | 向一个日期数据x加上y月,得到一个新的日期 | |
| next_day(x,'char') | x之后一周内的某天(按char给出)的日期 | 中文操作系统,char写星期几;英文操作系统,char写英文星期几;char用数字表示,1表示周日,2表示周一等 |
| last_day(x) | 返回某月x的最后一天 | |
| round(x,y) | 对日期进行四舍五入 | |
| trunc(x,y) | 对日期进行截取 |
next_day('01-9月-95','星期五')--输出01-9月-95开始的下一个星期五的日期 LAST_DAY(‘01-9月-95')--输出95年9月的最后一天的日期
round函数和trunc函数需要先使用to_date函数把字符串转成日期型数据后才可使用,默认都为天 round(to_date('25-7月-95'),'month')--把日期四舍五入到最近的月,输出该日期,结果为01-8月-95 trunc(to_date('25-7月-95'),'month')--把日期舍去月,输出该日期,结果为01-1月-95
显示了当前受雇时间小于35年的雇员的编号、受雇日期、当前受雇的月数TENURE、满八个月的复审日期REVIEW 、受雇后的第一个星期五以及受雇当月的最后一天。
select empno,hiredate,
MONTHS_BETWEEN(SYSDATE, hiredate) TENURE,
ADD_MONTHS(hiredate, 8) REVIEW,
NEXT_DAY(hiredate, 6) , LAST_DAY(hiredate)
from emp
where MONTHS_BETWEEN(SYSDATE, hiredate)/12<35;
-
转换函数
- to_char
- 用于日期型
to_char(date,'fmt') fmt必须用‘’括起来,并使用逗号与date分隔开
日期格式模型的元素

使用双引号可以添加普通字符
- 用于日期型
查询出所有在1981年雇佣的雇员信息。
select * from emp where to_char(hiredate,'yyyy')=1981;- 用于数值型
to_char(number,'fmt') 常用的数字格式化模式fmt

查询scott用户工资,显示格式为3,000.00
select to_chat(sal,'$9,999.00') from emp where ename='SCOTT'; --如果设置的是9,则不够的位数将不显示,如果设置为0,则表示会在前面补0 --数值型转字符串其位数一定要留够,不然会显示#- to_date,将字符串转成日期型数据 to_date(char[,'fmt']),如select to_date('2009 09 01', 'yyyy mm dd')
- TO_TIMESTAMP (char[, 'fmt'])转时间戳
- to_number(char[,'fmt'])字符串转数字
- nvl函数
- 作用:将null转为一个实际的值
- 语法nul(表达式1,表达式2)
- 当表达式1为空,则显示表达式2
- 表达式1数据类型可以是日期、字符、数值
- 两个表达式类型必须匹配
- 如:NVL(comm, 0),comm为null时显示0
- decode()函数实现逻辑判断(分支) 语法格式:decode(列或表达式,查找值1,结果值1 ,查找值2,结果值2 ,…… ,默认值 ) 显示部门编号为30的每个雇员相适应的税率 TAX_RATE,要求结果显示雇员名,工资,税率。 税率如下: ü 工资不足1000,税率为0, ü 工资在1000-1999税率为0.09, ü 工资在2000-2999税率为0.2, ü 其余税率为0.4
- to_char
select ename,sal,decode(sal/1000,0,0
,1,0.09
,2,0.2
,0.4)as "TAX_RATE"
from emp
where deptno=30;
单值函数
- nul2()函数
- 语法nul2(表达式1,表达式2,表达式3)
- 如果表达式1不为空,nul2返回表达式2
- 如果表达式1为空,nul2返回表达式3
SELECT ename, NVL2(comm, sal+comm,sal) "Income" FROM emp WHERE job like 'SALES%' ORDER BY job --查找job以sales开头的员工总收入 - nullif函数
- 语法:nullif(表达式1,表达式2)
- 功能:用于比较表达式1和表达式2,如果相等返回null,不相等返回1
SELECT ename,job, NULLIF(LENGTH(ename),LENGTH(job)) FROM emp --查找员工姓名,判断员工姓名和工作值长度是否相等 - coalesce(表达式1,表达式2,……,表达式n):返回表达式列表中第一个不为空的表达式值
```sql
select ename,sal,comm,
coalesce(comm,sal*0.1,100)"new commission"
from emp;
-- coalesce(comm,sal*0.1,100),若comm为空,则放回sal*0.1,如果sal为空则返回100
10. case表达式
```sql
select job,sal,
case job when 'SALESMAN' then sal*1.15
when 'CLERK' then sal*1.20
when 'ANALYST' then sal*1.25
else sal*1.40
end "new salary"
FROM emp;
子查询与多表查询
嵌套查询
格式:select 列名 from 表名 where 表达式 运算符(select 列名 from 表名)
--查询工资比雇员JAMES高的雇员姓名
select ename from emp
where sal>(select sal from emp where ename='JAMES');
--要求采用子查询方式完成从部门表DEPT和雇员表EMP中查询数据,显示所属部门名SALES的所有员工(显示雇员号、雇员名)。
select empno,ename
from emp
where deptno=(
select deptno from dept
where dname='SALES');
注意: 子查询要用括号括起来 子查询放在比较运算符右边 子查询中还可以有子查询 一般子查询中要用order by会与rownum一起使用
--在所有雇员中,查询工资最高的前3名职工(显示职工号、职工名、工资)。
select empno,ename,sal
from (select empno,ename,sal from emp
order by sal)
where rownum<4
子查询只返回一行一列的结果,可使用单行运算符

子查询结果多于一行,使用多行比较运算符
in :等于列表中的任意一项
any/all
any运算符
<=any 小于任意一个,小于最大值
>=any 大于任意一个,大于最小值
=any 相当于in
select empno,ename,job
from emp
where sal<any(
select sal
from emp
where job='CLERK'
)
and job<>'CLERK';
--查找工资小于clerk最高的工资的员工,且该员工工作不是clerk的员工信息
all运算符
>all:表示比所有的大
<all:表示比所有的小
<>all:相当于not in
select empno,ename,job
from emp
where sal>all(
select avg(sal)
from emp
group by deptno);
--查询工资大于所在部门平均工资的员工信息
SELECT ename,deptno,sal
FROM emp e
WHERE sal>(select avg(sal)
from emp
where deptno=e.deptno)
--查询工资大于部门平均工资的员工
多表操作,没有连接条件,则是完成笛卡尔乘积
--查询所有分公司的基本情况(公司号、公司名、部门号、部门名、部门地址)。包括没有设置部门的公司。其中公司表为COMPANY,部门表为DEPT1。
select c_id,c_name,deptno,dname,loc
from dept1 right join company on dept1.c_id=company.c_id
外部连接还可以使用符号(+),他可以出现在等值连接条件的左右侧,但不能同时出现在两侧,(+)放在缺少匹配信息的表一侧
--查询所有部门的信息(部门号、部门名、雇员名),包括没有员工的部门
SELECT e.ename, d.deptno, d.dname
FROM emp e, dept d
WHERE e.deptno(+) = d.deptno
ORDER BY e.deptno;
--等同于以下
SELECT e.ename, d.deptno, d.dname
FROM emp e right join dept d
on e.deptno = d.deptno
ORDER BY e.deptno;
--用连接完成
--查询工资比JAMES高的雇员姓名
select b.ename
from emp a,emp b
where a.ename='JAMES'
and b.sal>a.sal
--查询雇员表emp中受雇日期比KING早的雇员信息(雇员号、雇员名、受雇日期)。
select a.empno,a.ename,a.hiredate
from emp a,emp b
where b.name='KING'
and a.empno=b.empno
and a.hiredate>b.hiredate
集合查询
多个查询语句的结果可以做集合运算,单结果集的字段、数量和顺序应该一样
oracle的四个集合操作
| 操作 | 描述 |
|---|---|
| union | 并集,合并两个操作的结果,去掉重复的部分 |
| union all | 并集,合并两个操作的结果,保留重复的部分 |
| minus | 差集,从前面的操作结果中去掉后面操作结果相同的部分 |
| intersect | 交集,取两个操作结果中相同的部分 |
--dept1(deptno,dname,loc,d_type,c_id)
--company(c_id,c_name,c_registerday)
--查询全部的部门表DEPT1的部门名和公司表COMPANY的公司名
select dname from dept1
union
select c_name from company;
--查询公司号为01和02的两个公司中是否有同名的部门名。
select dname from dept1 where c_id='01'
intersect
select dname from dept1 where c_id='02'
--查询没有设置部门的公司号c_id
--分析:查询所有的公司号,查询有部门的公司号,求差集
select c_id from company
minus
select distinct c_id from dept1;
操作数据
插入数据
insert into 表名[列名,列名] values(列值,列值)
--向部门表中插入一新部门(部门号70,部门名为开发部,部门地址为福州)
insert into dept
values (70,'开发部','福州')
利用子查询向已存在的表中插入数据 语法:insert into 表名[(列名,列名……)] 子查询
--向已存在的表sales插入雇员表中工作岗位以SALES开头的所有记录:
insert into sales (empno,ename,job,sal)
select empno,ename,job,sal
from emp
where job like 'SALES%'
更改数据
update 表名 set 列名=新值 where 条件表达式
--更新dept表的数据,将部门号为70的部门地址由福州改为厦门
update dept set loc='厦门' where deptno=70;
--可以在where子句或者set子句中使用子查询。
update emp
set sal=(select losal
from salgrade
where grade=1)
where sal<(select losal
from salgrade
where grade=1)
删除数据
delete [from]表名 [where 条件表达式]
--删除部门号为70的部门信息
delete dept where deptno=70
基于另一个表来删除行 可以在where子句中使用子查询
--删除SALES部门下的所有雇员信息( SALES为部门名)
delete from emp
where deptno=(select deptno from dept where dname='SALES')
删除数据,使用truncate table 表名
truncate table dept1;
-- 删除dept1表中的所有记录
使用truncate table删除数据时,通常比delete快
truncate table操作不可回退,如果没有备份,删除的数据无法恢复
不触发表的删除触发器
truncate table不能删除带外键约束的被引用表中的数据
truncate table 默认使用drop storage,表示删除记录后回收记录占用的空间
truncate table reuse storage 保留删除的记录空间
合并操作
merge into 表名1 --需要将数据进行合并,保持合并数据的表名
using 表民2 --合并数据时使用的另一个表
on (条件表达式)--执行合并操作判断是否一致
when matched then--当条件表达式为镇,执行
update语句 --不需要提供表名
when not matched then--当条件为假时执行
insert语句 --不需要提供表名
--将dept1_old表中的数据合并到dept1中
merge into dept1 a
using dept1_old b
on a.deptno=b.deptno
when matched then
update set a.dname=b.dname,a.loc=b.loc,a.d_type=b.d_type,a.c_id=b.c_id
when not matched then
insert(a.deptno, a.dname, a.loc, a.d_type,a.c_id)
VALUES (b.deptno, b.dname, b.loc, b.d_type,b.c_id);)
事务
不可分割的整体称之为事务,一个事务的所有sql语句,要么全部执行,要么全部不执行
对数据库所做的修改,暂时不写入数据库,而是缓存起来,用户在自己的终端可以预览变化,知道全部修改完后,一次性提交并写入数据库,提交前,所做的修改都可以撤销
提交后不能撤销,提交成功后,其他用户可以通过查询浏览数据的变化
事物由一个或多个DML语句,一个DDL语句,一个DCL语句
事物提交前的特点

事物提交后的特点

事物撤销后的特点

数据库事物的基本属性:
- 原子性:事物要么完全成功,要么完全失败
- 一致性,数据库会保持一致性的状态,不存在局部数据
- 隔离性:在事务提交以前,该事务所作的更改,只对做更改的当前会话可见
- 持久性,事物完成后,就不能被取消
隐式事务处理
正常退出时,create drop alter grant revoke会发生事务的自动提交
若把环境变量autocommit设为on,则每执行一条DML就自动提交
异常退出,DML会回退
显式事务处理
commit 事务提交 rollback 事务回滚 savepoint 保存点名称:创建保存点,用于事务的阶段回滚 rollback to 保存点名称:回滚到保存点
总结
oracle自动标识一个事务
事务以一个DML语句开始
PL/SQL基础
PL/SQL允许过程控制语句和sql语句结合使用,是oracle特有的编程语言 PL/SQL将多条SQL语句组成一个单元或块,程序一次将整个块发送给数据库,不必每次一句地逐句发送,减少数据库调用次数,性能更高
PL/SQL语句块
PL/SQL是块结构化语言 语句块有:匿名块、过程(存储过程)、函数、触发器、包
编写规范: 定义变量,使用v_前缀 常量,c_前缀 游标,cursor 异常,e
块的分类
匿名块
命名块,能接受变量,能被调用,可声明为过程或函数,仅执行一动作是定义为过程,计算值时定义为函数

程序结果
匿名块的三个构成
声明(可选),执行(必须)和异常处理(可选)

块的实例
set serveroutput on--打开输出选项
begin
dbms_output.put_line(‘hello’);
--dbms_out是一个包,put_line是该包的一个过程,用.调用
end;
select语句中都必须有into 关键字(游标中的select除外),用于把数据库中取到的值赋给变量
select…into的结果只能有一行,若没有返回行,抛出no_data_found异常;若有多行,抛出too_many_rows
PL/SQL支持查询、DML和事务控制命令
SELECT、INSERT、UPDATE、DELETE
COMMIT、ROLLBACK、SAVEPOINT
标识符命名规则 必须以字母开头,长度不超过30 后可跟多个字母,数字0~9或<span data-formula=",#,_ 不区分大小写 不能与程序中引用的字段重名,重名视为列名 带双引号的标识符区分大小写
在执行块中为变量赋值的语句:= ; select into
数据类型
%type
%rowtype 语法变量名 表名或游标名%rowtype
" aria-hidden="true">,#,_
不区分大小写
不能与程序中引用的字段重名,重名视为列名
带双引号的标识符区分大小写
在执行块中为变量赋值的语句:= ; select into
数据类型
%type
%rowtype 语法变量名 表名或游标名%rowtype
v_dept dept%rowtype --声明行记录变量v_dept,其成员于dept表中各个列的列名数据类型都相同
v_dept.deptno --使用点号应用记录变量中的字段
--在匿名块中查询部门号为10的部门信息,并且显示查询结果信息“部门号10的部门名为***部门地址为****”
--%type
declare
v_dname dept.dname%type;
v_loc dept.loc%type;
v_deptno dept.deptno%type;
begin
select deptno,dname,loc into v_deptno,v_dname,v_loc from dept where deptno=10;
dbms_output.put_line('部门号'||v_deptno||'的部门名为'||v_dname||'部门地址为'||v_loc);
end;
--%rowtype
declare
v_dept dept.%rowtype;
begin
select deptno,dname,loc into v_dept.deptno,v_dept.dname,v_dept.loc from dept where deptno=10;
dbms_output.put_line('部门号'||v_dept.deptno||'的部门名为'||v_dept.dname||'部门地址为'||v_dept.loc);
end;


引用结合变量前面要加上“:”,程序结束后该变量仍然存在,其他程序可以继续引用。
在SQL*PLUS环境下显示该变量要用系统的print命令。 语法:print 变量名 ;


条件控制语句
if
if 条件表达式 then
语句1
else
语句2
end if;
elsif
if 条件表达式1 then
语句1;
elsif 条件表达式2 then
语句2;
……
else
语句n
end if;
end if 与if配对
case
case 选择器
when 表达式1 then 语句1;
when 表达式2 then 语句2;
……
else 语句n+1
end case;
选择器可以是复杂的表达式
case也可以作为表达式的一部分
如:变量名:=case 选择器
中部同上,但句末不带分号
end;
declare
v_sal emp.sal%type;
v_comm emp.comm%type;
v_empno emp.empno%type:=&v_empno;
begin
select sal into emp where emppno=v_empno;
v_comm:=case sal
when sal<1000 then v_comm*0.1
when sal<1500 then v_comm*0.15
when sal>1500 then v_comm*0.2
else 0
end;
update emp set comm =v_comm where empno=v_empno;
end;
循环控制
LOOP简单循环
基本循环,又称无条件循环
loop 循环语句; end loop;
退出语句exit;
实例:if 条件表达式 then
exit;
end if;
退出条件exit when 条件表达式
exit语句只能出现在循环中
while循环
while 条件表达式 loop 循环语句; end loop;
for循环
for 循环计数器变量 in[reverse][下限..上限]
loop
循环语句;
end loop;
reverse反转,从上限到下线输出

顺序控制语句 null什么都不用做,转到下一条语句 goto无条件跳转到某个标号 标号为带尖括号的标识符 标号是唯一的,且标号后是可执行语句或块 goto不能跳转到if、case、loop语句或块中
游标for循环
见游标
游标
游标相当于指针
游标类型
静态游标:结果集已经存在的游标
游标属性:%found;%notfound;%rowcount;%isopen
隐式游标
也叫sql游标,使用增删改查时自动产生
可以使用SQL进行访问
用户不能控制或处理隐式游标的信息,也不能打开或关闭,右PL/SQL自动管理
--更新数据
begin
update customer
set customer_name='wy'
where customer_id=4;
if sql%found then
commit;
DBMS_OUTPUT.PUT_LINE('行更新');
end if;
end
显式游标(ref游标):动态关联结果集的临时对象
在声明块中直接定义的游标
对于放回多条记录的查询语句进行处理
事先必须声明显示游标
利用显示游标跟踪当前正在处理的那行
允许被控制
显式游标
游标标记了活动集的当前位置,由多行查询返回的行集合称之为活动集

--利用游标依次检索前10个员工的编号和姓名
--%type
DECLARE
v_empno emp.empno %TYPE;
v_ename emp.ename %TYPE;
CURSOR c1 IS
SELECT empno, ename FROM emp;
BEGIN
OPEN c1;
FOR i IN 1..10 LOOP
FETCH c1 INTO v_empno, v_ename;
--into后的列和定义游标的select语句的列的数量相同,数据类型一致
dbms_output.put_line(v_empno||'--'|| v_ename);
END LOOP ;
close c1;
END;
--%rowtype
DECLARE
CURSOR emp_cursor IS
SELECT empno, ename
FROM emp;
emp_record emp_cursor%ROWTYPE;
BEGIN
OPEN emp_cursor;
FOR i IN 1..10 LOOP
FETCH emp_cursor INTO emp_record;
dbms_output.put_line(emp_record.empno||'--' ||emp_record.ename);
END LOOP;
close emp_cursor;
END;
--当查询结果集数量不足10人时,用属性%notfound提前退出循环
declare
cursor emp_cursor is
select empno,ename
from emp1;
v_emp emp_cursor%rowtype;
begin
if not emp_cursor%isopen then
open emp_cursor;
end if;
for i in 1..10 loop
fetch emp_cursor into v_emp;
exit when emp_cursor%notfound;
dbms_output.put_line(v_emp.empno||v_emp.ename);
end loop;
close emp_cursor;
end;
--游标FOR循环完成会自动打开游标和关闭游标
declare
cursor emp_cursor is
select empno,ename
from emp;
begin
for v_emp in emp_cursor loop
-- 隐式地打开游标并对游标进行提取
exit when emp_cursor%rowcount>10;
dbms_output.put_line(v_emp.empno||v_emp.ename);
end loop; -- 隐式地关闭游标
end;
游标for循环
for 记录变量名 in 游标名 loop
语句;
……;
end loop;
--用游标FOR循环完成检索部门名为SALES的所有员工的姓名,工资。
declare
cursor emp_cursor is
select ename,sal,dept,dname,sal
from emp,dept
where emp.deptno=dept.deptno
and dept.dname='SALES';
begin
for v_row in emp_cursor loop
dbms_output.put_line(v_row.ename||v_row.sal);
end loop;
end;
--使用子查询的游标式FOR循环,不需声明游标
BEGIN
FOR emp_record IN (SELECT ename,sal
FROM emp
where deptno=30)
LOOP
DBMS_OUTPUT.put_line(emp_record.ename||','|| emp_record.sal);
END LOOP;
END;
带有参数的游标
--带参游标定义
cursor cut_emp(p_deptno number:=10)
cut_emp 游标名
p_deptno 形参
is select * from emp
where deptno=p_deptno;
--带参游标调用
open 游标名(实参)
for 记录变量 in 游标名(实参)loop
……
end loop;
--在匿名块中输入某部门号,检索该部门的所有雇员姓名和工资。
--要求使用有参游标,在游标中使用参数传递部门号,若未传递参数则默认检索部门号10的雇员信息。
declare
cursor emp_cursor(p_deptno emp.deptno%type:=10)
is select * from emp
where deptno=p_deptno;
v_emp emp_cursor%rowtype;
begin
for v_emp in emp_cursor(&v_deptno) loop
dbms_output.put('姓名:' || v_emp.ename);
dbms_output.put_line(',工资:' || v_emp.sal);
end loop;
end;
--while循环
begin
open cur_emp(&v_deptno);
fetch cur_emp into v_emp;
while cur_emp%found loop
dbms_output.put('姓名:' || v_emp.ename);
dbms_output.put_line(',工资:' || v_emp.sal);
fetch cur_emp into v_emp;
end loop;
close cur_emp;
end;
使用游标更新或删除数据
--检索部门号为30的每一个员工,将工资提高10%。
DECLARE
CURSOR sal_cursor IS
SELECT sal
FROM emp
WHERE deptno = 30
FOR UPDATE OF sal NOWAIT;--创建不等待的游标,其中sal是要更新数据的表中的列
BEGIN
FOR emp_record IN sal_cursor LOOP
UPDATE emp
SET sal = emp_record.sal * 1.10
WHERE CURRENT OF sal_cursor;
END LOOP;
COMMIT;
END;
--嵌套游标
--当父游标检索一条记录时,就会遍历一次子游标。
--在嵌套游标中使用参数,检索各部门的雇员信息
declare
cursor cur_dept is
select deptno from dept;
cursor cur_emp(p_deptno in emp.deptno%type) is
select * from emp
where deptno = p_deptno;
begin
for v_dept in cur_dept loop
dbms_output.put_line('部门' || v_dept.deptno);
for v_emp in cur_emp(v_dept.deptno) loop
dbms_output.put('姓名:' || v_emp.ename);
dbms_output.put(',职务:' || v_emp.job);
dbms_output.put_line(',工资:' || v_emp.sal);
end loop;
end loop;
end;
异常处理

异常部分从exception开始
允许多个when
离开块之前只能执行一个处理器
块中最多只能有一个others子句,且when others必须是最后一个子句
预定义异常

DECLARE
v_ename emp.ename%TYPE;
v_sal emp.sal%TYPE;
BEGIN
select ename,sal into v_ename, v_sal
from emp
where empno= 7369;
DBMS_OUTPUT.PUT_LINE('雇员名称:'|| v_ename);
DBMS_OUTPUT.PUT_LINE('雇员工资:'|| v_sal);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('NO_DATA');
WHEN TOO_MANY_ROWS THEN
DBMS_OUTPUT.PUT_LINE('TOO_MANY');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(' OTHERS ');
END;
处理非预定义异常

处理用户自定义异常
declare
v_sal emp.sal%type := &v_sal;
v_cnt number;
e_negative exception;--定义异常
begin
if v_sal < 0 then
raise e_negative; --抛出异常
else
select count(*) into v_cnt from emp
where sal = v_sal;
dbms_output.put_line(v_cnt || '个雇员获得该工资');
end if;
exception
when e_negative then--处理异常
dbms_output.put_line('您输入的工资是负数!');
end;
存储过程
创建存储过程
--格式
create or replace procedure 过程名
as | is
说明
begin
执行
exception
错误处理
end 过程名;
--创建过程P_DEPT,实现功能:输出各部门的部门名称
create or replace procedure p_dept
as cursor cur_dept is
select dname from dept;
begin
for v_dept in cur_dept loop
dbms_output.put_line('部门名称:' || v_dept.dname);
end loop;
end p-dept;
--编译成功也不会输出结果
--查看编译错误
show error
--执行存储过程
--使用命令执行
exec p_dept;
--在PL/SQL语句块中调用过程
begin
p_dept;
end;
--修改存储过程
alter procedure 过程名 compile;

传入传出参数
in参数(只读)
默认参数模式
可以有默认值
定义形参的默认值

参数的使用


一般情况下,定义过程的时候,建议没有默认值的in参数放在参数列表的最开始,其后是out类型的参数,然后是in out 类型的参数,最后才是具有默认值的in参数
/*编 写 给 雇 员 增 加 工 资 的 存 储 过 程
CHANGE_SALARY,通过参数传递要增加工资的
雇员编号和增加的工资额(默认雇员编号7788和
增加的工资额为100),更改完雇员工资后,再通
过参数传出增加后的工资。
步骤1:登录SCOTT账户。
步骤2:在SQL*Plus输入区中输入以下存储过程
并执行:
*/
CREATE OR REPLACE PROCEDURE CHANGE_SALARY(pi_empno IN
NUMBER DEFAULT 7788,pi_raise IN NUMBER DEFAULT 100,po_sal
OUT number)
AS
V_ENAME VARCHAR2(10);
V_SAL NUMBER(5);
BEGIN
SELECT ENAME,SAL INTO V_ENAME,V_SAL
FROM EMP
WHERE EMPNO=pi_empno;
po_sal:=V_SAL+pi_raise;
UPDATE EMP
SET SAL=po_sal
WHERE EMPNO=pi_empno;
DBMS_OUTPUT.PUT_LINE('雇员'||V_ENAME||'的工资被改为
'||TO_CHAR(po_sal));
COMMIT;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('发生错误,修改失败!');
ROLLBACK;
END;
--输入以下程序调用存储过程
DECLARE
v_newsal NUMBER;
BEGIN
CHANGE_SALARY (7782,300,v_newsal);
DBMS_OUTPUT.PUT_LINE('增加后的工资为:
'||v_newsal);
END;
函数
/*创建函数f_getName,根据传入的雇员编号
返回雇员姓名。其中要有找不到该雇员的异常处理*/
create or replace function f_getName
(pi_empno emp.empno%type)--函数的参数只能使用in参数
return varchar2
as
v_ename emp.ename%type;
begin
select ename into v_ename from emp
where empno = pi_empno;
return (v_ename);
exception
when no_data_found then
return ('No data found');
when others then
return ('Other errors');
end f_getName;
--可存在多个return语句,但只执行其中一个
--使用函数的两种方法
-- (1)将函数的返回值赋值给一个变量
declare
v_no number := 7369;
v_name varchar2(20);
begin
v_name := f_getname(v_no);
dbms_output.put_line(v_name);
end;
-- (2)将函数的返回值赋值给一个全局变量
SQL>variable tt varchar2(10);
SQL>exec :tt:=f_getName(7788);
-- (3)在SELECT语句中使用
select empno, f_getname(empno)
from emp;
drop procedure 过程名;
drop function 函数名;
触发器
触发器和存储过程的区别:唤醒方式不同
- 存储过程需要调用,触发器在执行某些操作的时候会自动执行
- 创建触发器是不带参数的
- 一般执行DML语句自动执行触发器

--:old;:new只能用于行触发器,for each row 行触发器
--创建触发器tr_emp_insert ,使用当前系统日期作为新增雇员的雇佣日期。
create or replace trigger tr_emp_insert
before insert on emp
for each row--影响多少行
begin
:new.hiredate := sysdate;
end tr_emp_insert;
--触发器中不能使用事务控制语句
create or replace trigger tr_log
after delete on dept
begin
insert into t_logs(log_time, log_user, log_opt)
values(sysdate, user,
'DELETE ON dept');
-- commit; -- 触发器中不能使用事务控制语句
end tr_log;
--when子句,只能在行触发器中使用,when子句中的:new;:old都不需要前缀冒号
--创建触发器tr_sal_2000 ,在更新雇员工资前触发,若更新后的工资低于2000则将工资设置为2000。
create or replace trigger tr_sal_2000
before update of sal on emp
for each row
when (new.sal < 2000)
begin
:new.sal:=2000;
end tr_sal_2000;
--等价于
create or replace trigger tr_sal_2000
before update of sal on emp
for each row
begin
if :new.sal > 2000 then
:new.sal:=2000;
end if;
end tr_sal_2000;
替代触发器instead of
定义与数据库视图上,作为行触发器创建,不需要for each row insetad of触发器用于修改一个本来无法修改的视图
本文章使用limfx的vscode插件快速发布