<strong>公司是否发生间接融资</strong>
1数据集介绍
在本数据集中,介绍了新三板公司中一些公司的基本情况。针对这些信息,旨在分析出公司发生间接融资的概率,针对投资人的需求,使用数据分析做出正确的判断。
2.问题界定
主业务问题:基于k近邻算法,预测公司是否发生融资。
3.数据准备
1.导入数据分析工具和文件
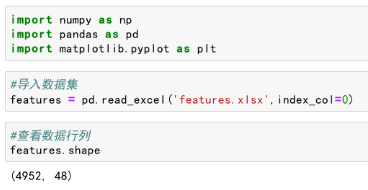
2.数据检视
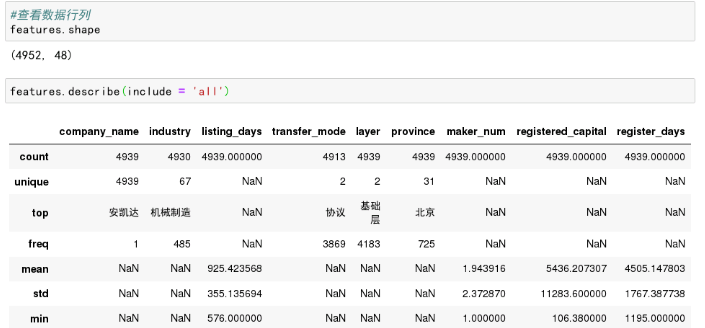
3.数据质量初步分析
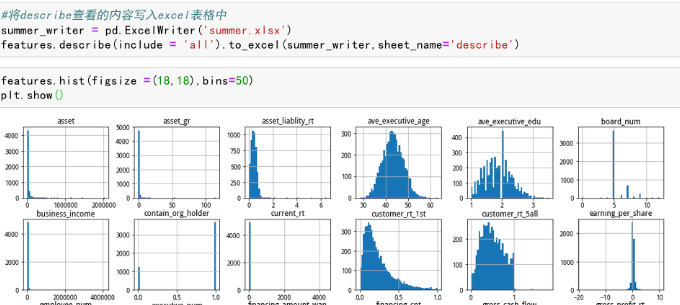
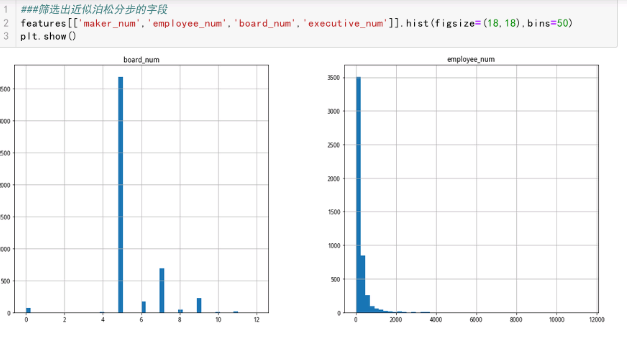
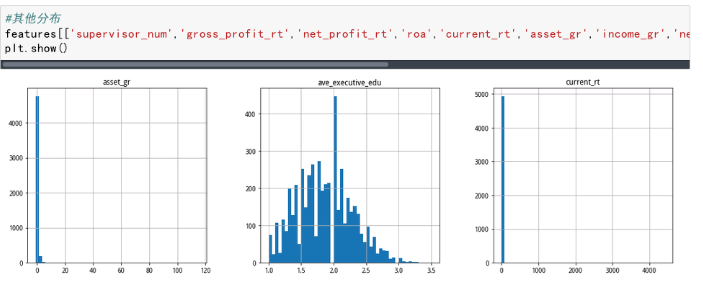
根据数据的直方图可以看出不同字段的分布情况
属于泊松分布的字段:
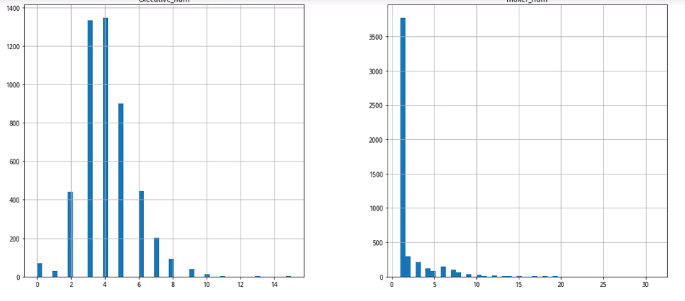
maker_num, employee_num, board_num,executive_num
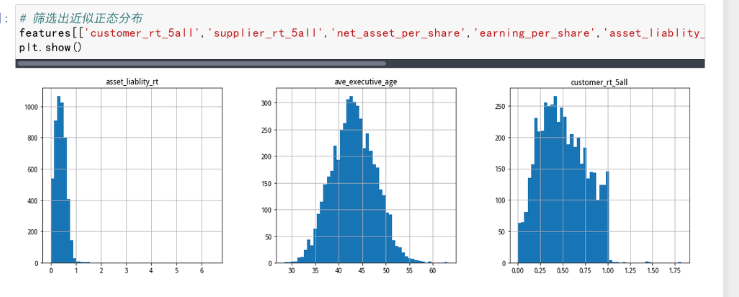
属于正态分布的字段
customer_rt_5all,supplier_rt_5all,net_asset_per_share,earning_per_share,asset_liablity_rt,ave_executive_age,holder_rt_1st
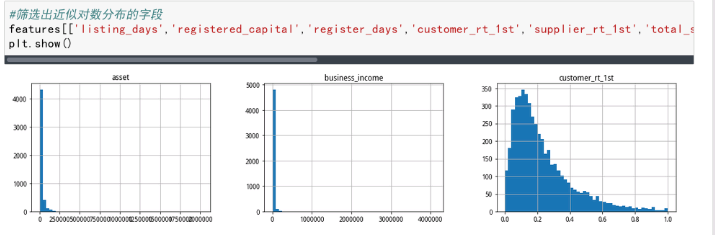
属于对数分布的字段
listing_days,registered_capital,register_days,customer_rt_1st,supplier_rt_1st,total_stock_equity,business_income,asset,liability,gross_cash_flow
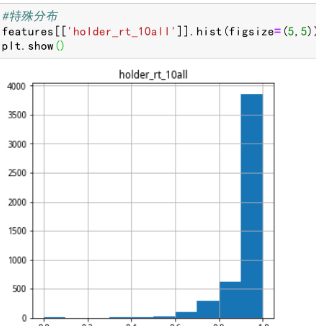
特殊分布字段:
holder_rt_10all
其他分布字段:
supervisor_num,gross_profit_rt,net_profit_rt,roa,current_rt,asset_gr,income_gr,net_profit_gr,ave_executive_edu
4.数据预处理
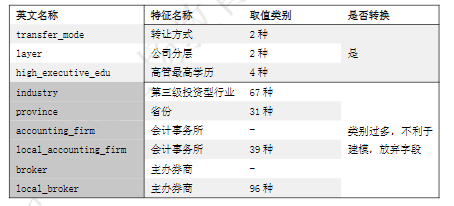
1.可放弃字段 本案例中一共48个字段,共有七个字段可以放弃 部分字段放弃依据表
| 英文名称 | 特征名称 | 放弃依据 |
|---|---|---|
| company_code | 公司代码 | 公司标识,不参与数据建模 |
| company_name | 公司名称 | 公司标识,不参与数据建模 |
| trading_days | 交易日期 | 交易发生后字段,不用与分析 |
| trading_price | 交易价格 | 交易发生后字段,不用与分析 |
| total_transaction_amount | 交易总金额 | 交易发生后字段,不用与分析 |
| financing_amount_wan | 融资金额 | 交易发生后字段,不用与分析 |
| outway | 公司去向 | 与业务问题无关 |
需要转换的字段情况
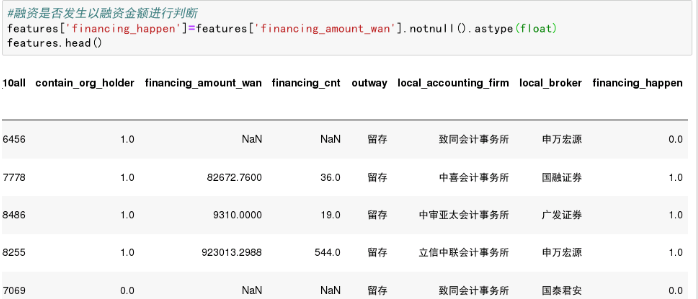
2.模型输出组变量
在放弃字段中,选择total_transaction_amount,作为输出组变量特征
3.异常值处理
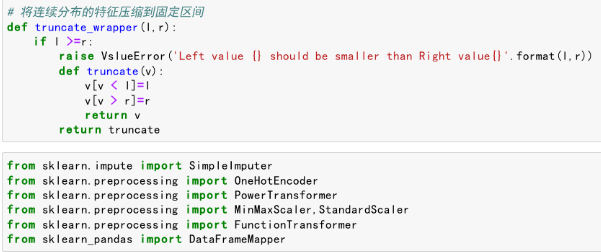
导入数据处理需要的库,创建函数
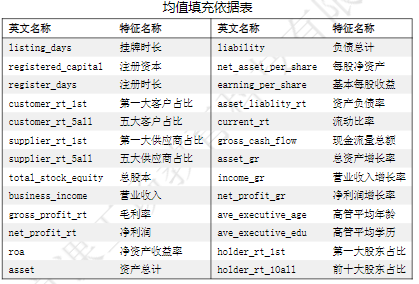
数据集中有部分数据存在缺失值
对于连续变量使用均值填充
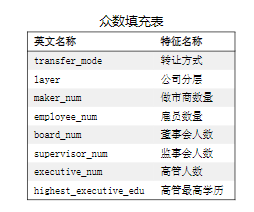
对于非连续变量使用众数填充
对于二元变量0值填充,存在为1,不存在为0
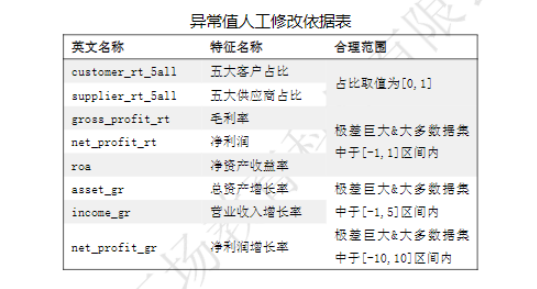
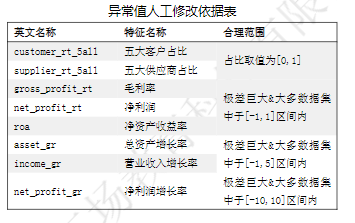
对于数据的异常值处理




数据分割

重采样

5.数据建模
k近邻算法

网格搜索


 可以看出准确率还是比较高的,比没调参数之前搞了0.2个点。
可以看出准确率还是比较高的,比没调参数之前搞了0.2个点。

制作混淆矩阵


 可以看出精度较高,但召回率不太高,案例的目标并不是捕获少数类,所以不用太计较召回率的大小。
使用f1分数发现,得出的结果不算太高,这是因为召回率较低的原因,由于并不追求高召回率,所以f1分数得出这个结果还是不错的。
可以看出精度较高,但召回率不太高,案例的目标并不是捕获少数类,所以不用太计较召回率的大小。
使用f1分数发现,得出的结果不算太高,这是因为召回率较低的原因,由于并不追求高召回率,所以f1分数得出这个结果还是不错的。


 虚线表示随机预测曲线,fpr=tpr。表示的随机预测模型的效果。
对于roc曲线,取左上角最好,在结果中,画出的曲线都在左上角,表明这个模型还是可以的。
虚线表示随机预测曲线,fpr=tpr。表示的随机预测模型的效果。
对于roc曲线,取左上角最好,在结果中,画出的曲线都在左上角,表明这个模型还是可以的。
 对于不平衡数据使用平衡准确度balanced accuracy来计算他的准确度是比较合适的。
这个结果为74.63%,说明模型的准确度还是不错的,不是很高,但也不是很低,中规中矩。
对于不平衡数据使用平衡准确度balanced accuracy来计算他的准确度是比较合适的。
这个结果为74.63%,说明模型的准确度还是不错的,不是很高,但也不是很低,中规中矩。
本文章使用limfx的vscode插件快速发布