实现一个String 类
C/C++ 在基本数据类型中没有提供独立的字符串方案,默认情况下只能通过字符数组实现,但是这样不方便实现更多字符串的处理功能。因此C 提供了string.h 来支持更多字符串处理功能, C++ 提供了string 头文件。但是与C不同的是C++ 通过OOP思想将字符串封装成一个类,使程序员在操作字符串上可以与操作普通基础数据类型的变量一致,降低了学习成本,也方便了程序员编写相关代码。
此篇笔记基于《C++ Primer Plus 6th》,来学习C++对于字符串处理的思路。
1. String类的需求分析
1.1 字符串的核心需求
首先,字符串最核心的功能使存储字符串,同时它还应该不浪费内存的存储字符串,这就表明这个字符串对象必须在程序运行过程中被创建,并且由用户输入的内容来决定对象本身在内存中的大小。字符串类的核心需求可总结为:
- 能够存储字符串
- 根据输入的字符串来决定分配的内存多少
由此可确定这个类存储字符串的部分需要用到动态内存分配技术;而存储字符串的本质就是一个动态的字符型数组,通过指针对它进行访问。
1.2 字符串的功能需求
字符串类只能存储字符串肯定是不够的,这样太浪费类的强大功能。因此除了存储字符串本身以外,我们还希望它能有其他的功能:
-
能够像基本数据类型的变量一样进行操作;包括 创建、初始化、赋值、对逻辑运算符的支持,能与普通 变量一样通过
cout进行输出 , 通过cin进行从键盘上获取值,即:- 创建:
int a--String str; - 初始化:
int a = 0--String str = "hello"; - 赋值:
a = 10--str = "Oh!"或a = b--str1 = str2; - 逻辑运算:
a > b--str1 > str2包括 大于(>), 小于(<), 是否相等(==); - 常规输入输出:
cin >> a,cout << a--cin >> str,cout << str;
- 创建:
-
能够像普通数组一样索引具体的某个字符
a[2]--str[2]; -
能够给出此字符串的长度;
2. 具体实现
2.1 私有成员
为了存储字符串,因此我们需要一个字符型的数组,同时它可以通过实际的输入来决定自己所占内存的多少。因此我们不应改直接定义数组,而是应该定义一个字符型指针,用它来指向动态分配的字符数组内存。另外创建数组无法避免的是指定数组的大小,因此我们需要一个变量来存储字符的长度。最后,我们需要指定一个字符串长度限制,由于所有的String对象限制应该一致,没有必要每个对象都申请一个内存块来保存这个字数限制,所以我们可以用静态常量; 具体实现代码如下:
// Part of private members of String class
class String
{
private:
char* str; // pointer to char array
unsigned int len; // the length of input string
static const int CINLIM = 80;
};
2.2 功能实现
上述的所有功能需求可以被分成三类:
- 构造函数与析构函数
- 显式定义默认构造函数
- 以字符串数组为参数的构造函数
- 以String对象引用为参数的复制构造函数
- 显式定义析构函数
- 运算符重载
- String对象间的赋值运算符
= - String对象与C风格字符串间的赋值运算符
= - 索引运算符
[]
- String对象间的赋值运算符
- 友元函数
- String对象间的比较大小
<和> - String对象间的等于判断
== - 用cout 和cin 输出和输入
<<和>>
- String对象间的比较大小
这些运算符和函数都应在对象之外能被使用,因此他们的访问控制都是'public',下面来看看他们的具体实现
2.2.1 默认构造函数
默认构造函数是当类定义中没有构造函数时隐式生成的。也就是说一个类一定会至少有一个构造函数,但在用户自定义构造函数被显式地定义后,编译器将不再生成构造函数。实际上,在实例化类的过程中,构造函数将被调用。而默认构造函数内部不包含其他代码,这也就意味着申请到的内存中保存的是垃圾值,以下是隐式生成的构造函数:
String() { }
它的存在为创建对象时参数为空提供了支持:
String str;
//equals
String str();
为了方便日后使用,我们需要更改默认构造函数,让它具备初始化字符数组的功能(动态分配的内存块最好都要初始化)。以下是自定义默认构造函数的代码:
String::String ()
{
len = 0;
str = new char[1];
str[0] ='\0'; //default string
}
它将默认字符数组长度设置为1用来保存空字符,同时将字符串长度设置为1以得到默认情况下真实的字符串 长度。
这里有个问题,既然这个动态分配的数组只有一个成员,为什么不直接用 str = new char;语句而是用str = new char[]; 语句?
我们可以想到,这两个语句分配的内存数量是相同的;唯一的区别在于后者与类析构函数兼容,而前者不兼容。析构函数定义如下:
String::~String()
{
delete[] str;
}
delete[] 与 new[] 、 空指针兼容,因此更改后的默认构造函数后两行,可以用空指针代替:
// default
str = new char[1];
str[0] ='\0'; //default string
// two lines above is equal to :
str = 0;
// or
str = nullptr; // new key word in C++11
str = NULL; // old fashion
// above two lines all signifying null pointer
但是delete[] 与 new 不兼容,与其兼容的是 delete,不兼容的具体表现为,如果用 delete[] 释放通过new关键字申请的内存,我们将无法预知其后果。即无法得知是否正确释放内存。
无法与delete[]兼容的其他语句:
char words[15] = "bad idea"; // if we have an array for testing
// don't compatible with delete[]
char* p1 = words;
char* p2 = new char;
char* p3;
2.2.2 其他构造函数
为了提供能够初始化成指定字符串这一功能,我们需要添加一种能够传递字符数组到对象内部的构造函数,这就引出了到底是用值传递,还是用指针传递。很显然虽然指针传递比值传递多一个创建指针的步骤,但它在传递长字符数组时有压倒性的优势:传递长数组的指针要远快于传递长数组的值。因此我们应当用char* 来当这一构造函数的参数,同时我们不希望此构造函数能够更改原字符串。由此我们确定了这一构造函数的原型:
String(const char* s);
此构造函数的定义如下:
String::String (const char* s)
{
len = std::strlen(s); // set size
str = new char[len + 1]; // allot storage
std::strcpy(str, s); // coping string
}
注意: 代码中不用 str = s 的原因有二,且十分重要
- 如果在动态分配后再给str赋值,则动态分配的内存将再也无法被访问。
- 如果直接使用此语句,则实际上str内保存了原字符数组的地址,如果原字符数组是一个用于临时存放输入内容的数组,这么做将导致每次输入都会改变所有String对象的值,导致String类失去意义。
设计一个专门的复制构造函数也是十分有必要的。在解释其原因之前,我们需要知道什么是复制构造函数(copy constructor)以及它将在什么情况下被调用。 先来看它的函数原型:
String(const String &);
可以看出,他是以自己相同类型的其他对象的引用作为参数的构造函数。这就意味着它用于将一个对象复制到新的对象中,即在初始化过程中传递参数。看下面这段代码:
int a, b;
a = b;
String str2;
// call copy constructor
String str1 = str2; //note
String str1 (str2);
String str1 = String(str2); //note
String* p_str = new String(str2);
为了让String类的对象可以通过与变量之间赋值一样相互传递自己的值,我们需要添加复制构造函数,最后这第6到9行代码都将导致复制构造函数被调用。
注意, 复制构造函数同默认构造函数一样会在程序员没有给出显式定义时自动生成。默认复制构造函数是将对象中的非静态成员逐个的复制给另外一个对象;由于这些成员有可能是私有的,所以程序员手动逐个复制无法实现。
另外上面第6行和第8行代码可能会使用复制构造函数直接创建新对象,也可能创建一个临时对象,然后将临时对象的内容赋给新对象。
当函数按值传递对象,或函数返回对象时,都将使用复制构造函数。
就是默认复制构造函数的逐个复制成员这里将出现问题:
一般来讲,如果对象里由一些整型、浮点型的成员,直接按值传递没有任何问题,就像一个整型变量复制给另一个一样;但是在复制由动态内存分配生成的指针变量时,将只传递指针,而不创建新的内存副本,即潜复制(shallow copy)。
应用在本例中即:新的String对象中str将指向老String对象所指向的内存。这很明显是个严重的bug,复制得来的String 对象只要一个改变了值,其他的也将一同被更改。更要命的是如果一不小心将其中一个对象析构,则其他的对象str将指向一个不由程序合法控制的内存块,这是极度危险的。 再加入有可能创建的临时对象的情形,这些临时对象将在完成了传递任务后被析构,那么新的对象所指向的内存块不就直接非法了嘛?
这也是原书StringBad类(未显式添加复制构造函数)结果乱码的原因所在。
默认复制构造函数不说明其行为,也不会指出创建过程,在一些需要记录创建了多少个对象的类中,这将导致计数器出错,就如原书不显式添加复制构造函数的String类版本一样,在最后析构函数调用时出现计数器值为负的情况。
由此看来,一旦类需要指向动态的内存块,都需要重新编写合适的复制构造函数。
原书的复制构造函数定义如下:
String::String(const String & st)
{
len = st.len; // same length
str = new char [len + 1]; // allot space
std::strcpy(str, st.str); // copy string to new location
}
这种在另外的内存块中存放副本的复制形式被称为(深复制)。
原书对于深浅复制的模型对比:
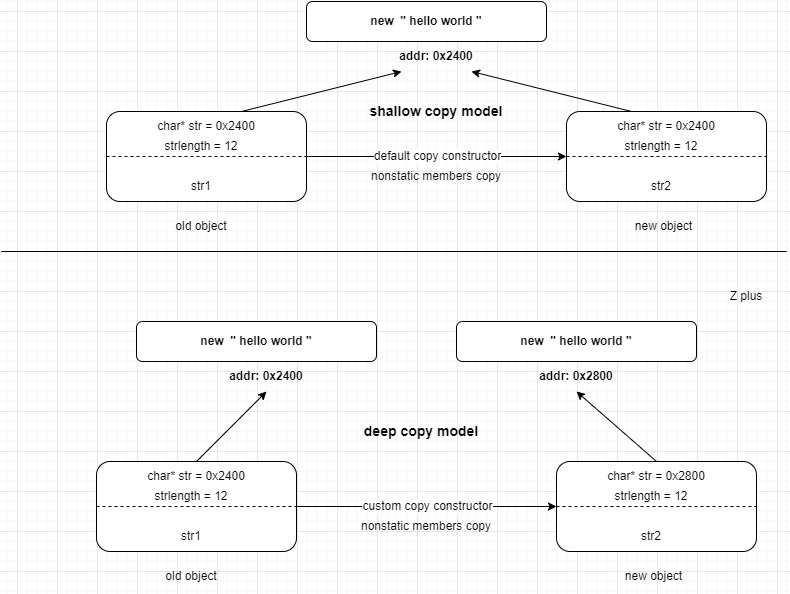
2.2.3 常规功能
根据需求,我们需要给String类添加能够与普通变量一样的使用的特性。 具体为:
- 通过 '=' 运算符完成赋值,包括字符串常量对String 对象赋值, String 对象给String对象赋值。
- 通过索引运算符 '[]' 来索引String对象中的字符。
- 输出String对象中字符串的长度。
一般情况下,'='只能被用在相同基本数据类型或能正常转换的两种数据类型之间,而往往不能满足用户自定义类型(类)的需求,因此我们需要重载 '=' 运算符。 以下两行原型分别对应第一点两种情况
String & operator= (const String & st); // change shallow copy to deep copy
String & operator= (const char* s); // object assigned by constant string
对应的定义如下:
String & String::operator= (const String& st) // 同类实现 1
{
if(this == &st) // avoid self assignment
return *this;
delete[] str; // free space of old string
len = st.len; // same length
str = new char[len + 1];
std::strcpy(str,st.str);
return *this;
}
//assign a C string to a string
String & String::operator= (const char* s)
{
delete[] str;
len = std::strlen(s);
str = new char[len + 1];
std::strcpy(str, s);
return *this;
}
在重写String对象对拷的赋值运算符重载中,我们需要首先排除自我复制,通过查看赋值运算符右边的地址(&st)是否与接收对象的地址(this)相同来完成的。this 是一个指针,*this才是它指向的对象。
如果地址不同,则释放当前str所指向的内存。如果不首先将其释放,则将新的地址赋值给str后,程序再也无法访问老的内存,从而导致内存浪费。最后分配足够的内存空间,并把字符串内容复制到新的内存单元中。
最后将当前对象返回(*this)即完成了深复制。
2.2.4 常规运算
若要判断一个字符串是否大于另一个字符串,可以判定这个字符是否在另一个字符前,若成立,则 '<' 就返回true,否则返回false。但在本例中将应用标准库中strcmp()函数(在头文件cstring中声明),它将按照字母顺序,第一个参数位于第二个参数之前就返回负数,相等返回0,大于返回负数,因此 '小于' 运算可以这么写原型:
friend bool operator< (const String & st1, const String & st2);
由于 大于、小于和等于这种运算符并不在类默认支持的运算符之中,要让类支持这样的运算,就得用到友元或内联,这里我们用友元实现,因为相比于内联函数,友元不仅可以让两个String对象比较,还能让String对象与一般的字符串常量比较。
同时, 我们不应该让此方法改动两个待比较的String对象,所以两个参数都用const修饰。
根据strcmp()函数的作用,我们可以这么定义这个运算符函数:
// version 1
bool operator< (const String & st1, const String & st2)
{
if(std::strcmp(st1.str, st2.str) < 0)
return true;
else
return false;
}
// version 2
bool operator< (const String & st1, const String & st2)
{
return (std::strcmp(st1.str, st2.str) < 0);
}
// prototype
friend bool operator> (const String & st1, const String & st2);
// definition version 1
bool operator > (const String & st1, const String & st2)
{
return (std::strcmp(st1.str, st2.str) > 0);
}
// version 2
bool operator> (const String & st1, const String st2)
{
return st2 < st1;
}
对于版本2, 由于我们已经定义了小于运算, 所以可以通过小于运算来表示大于运算。
相应的,判断两个字符串是否相等也可以这么写,'==' 运算符函数的原型与定义如下:
//prototype
friend operator== (const String & st1, const String & st2);
//definition
operator== (const String & st1, const String & st2)
{
return (std::strcmp(st1.str, st2.str) == 0);
}
2.2.5 输出
C++中输出和输入分别靠std::ostream 和 std::istream 两种类型的对象完成的。如:
std::cout << "hello world";
其中cout就是ostream类的对象,所以我们可以重载 << 和 >> 运算符来完成字符串的输入和输出。
同时我们发现,不管是 '<<' 还是 '>>' 第一个参数都是ostream 对象或者是 istream 对象;同时输出函数不应改变String对象的内容,因此它应该在输出函数中被 const 关键字修饰,但是输入函数需要对String对象进行修改,所以不能用const 修饰它,因此这两个函数的原型可以这样写:
friend void operator<< (std::ostream & os, const String & st);
friend void operator>> (std::istream & is, String & st);
其中输出函数的定义比较简单:
void operator<< (ostream & os, const String & st)
{
os << st.str;
}
这样我们就可以和普通变量一样输出String对象了,但是有个问题,如果想跟cout << "hello " << "world" << endl; 这样通过 << 来连续输出,就会发现出错,原因是 cout << st 会被翻译成:
operator<<(cout, st);
但是根据定义,这个函数没有返回值,而 << 运算符前面必须是ostream 类的对象。因此我们要对这两个函数进行更改,最终实现如下:
// prototypes
friend std::ostream & operator<< (std::ostream & os, const String & st);
friend std::ostream & operator>> (std::istream & is, String & st);
// definitions
std::ostream & operator<< (std::ostream & os, const String & st)
{
os << st.str;
return os;
}
std::istream & operator>> (std::istream & is, String & st)
{
char temp [String::CINLIM];
is.get(temp, String::CINLIM);
if(is) // input check
st = temp;
// clear input cache
while(is && is.get() != '\n')
continue;
return is;
}
这里比较复杂的是输入函数。输入函数首先要确保自己获取的字符串不会超过长度限制,所以输入函数创建了一个以长度限制为数组长度的临时数组,用于临时存储读入的字符,不通过get()直接将内容导入string对象的原因是:即便设置了长度限制,只将长度限制内的字符读入,多余的丢弃。
但是还是有机会出现问题:如果到了文件尾(EOF)或读入一个空行,直接读入将重复无意义的赋值,并导致输入bug,因此我们需要判断读入过程中 is 对象是否碰到了EOF或空行;解决方案即加一个if判定,原理是当遇上如上两种情况时将导致输入失败,is会返回false。
除此之外,如果输入的字符个数大于80,则多出的部分将保留在输入缓存(input cache)中,为了让下次调用输入函数不出错,我们需要在返回is对象之前清空输入缓存。
输入函数拥有一个istream引用的返回值原因和输出函数一致。
3. 主函数中的注意点
原书对这个类的实际应用是一个先提示用户输入,然后存储字符串到String对象数组中,并现实他们。最后指出哪个字符串最短,哪个字符串按字符顺序拍最前面的程序,其中按行多次从输入缓存输入字符串的解决方案值得学习,代码如下:
for(i = 0; i < ArSize; i++)// catch string block start
{
cout << i + 1 << ": "; // give the number to user
cin.get(temp, MaxLen); // get chars from cache with length less than 'Maxlen'
//clear cache, ready for next cin.get()
while (cin && cin.get() != '\n') // clear if input cache contains some chars
continue;
// empty line check
if(!cin || temp[0] == '\n') // empty line?
break; // logic : cin is false or the first char of temp is '\n'
else
saying[i] = temp; // overloaded assignment, a String object is assigned with other String object
}
打头的for循环用于迭代String对象数组元素,通过这个循环来对所有元素赋值。它
- 将第一行读入临时字符数组中;
- 用while循环清除多余字符,判定语句中加入cin来确保当且仅当输入缓存中有字符才清除输入缓存。
- 检查读入字符串是否是空行,不是空行才将字符串放入String对象数组。加这个判定的原因是我们只给
>>运算符加了空行检查。
本文章使用limfx的vscode插件快速发布