数据预处理
数据预处理的重要性
在数据挖掘过程中,数据预处理是不可或缺的部分
- 大数据应用中数据的典型特点是独立的,不完整,含噪声和不一致
- 大部分数据挖掘算法对数据质量以及数据规模有特殊要求,通过数据预处理能有效的提高数据的质量,为数据挖掘过程节约大量时间和空间
ETL概述
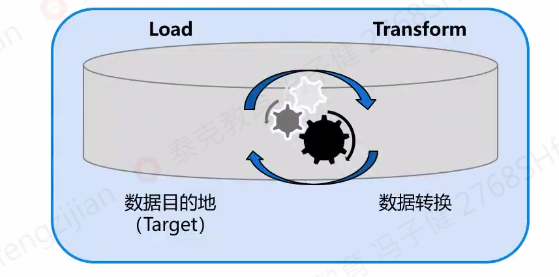
- ETL是一个数据管道,负责将分布的,异构的数据(Extract阶段)根据一定的业务规则进行数据清洗,转换,集成(Transform阶段),最终将处理后的数据加载到数据目的地(Load阶段),比如数据仓库
- ETL为企业提供了分析历史数据的可能
- ETL提高了企业工作效率,开发人员可以快速处理数据,省去了编写复杂代码的过程
- ETL提供了统一的视角来观察,统计,分析数据,促进跨部门,跨组织的合作,为企业决策提供良好的数据支撑
数据抽取
数据源:Oracle,SQL Server,Flat Data,Teradata 抽取中需要注意的点:
- 检查数据类型
- 确保数据完整
- 去除重复数据
- 去除脏数据
- 确保导出数据属性与源数据一致
数据抽取的三种方式:
- 更新提醒(Update Notification)
- 增量抽取(Incremental Extraction)
- 全量抽取(Full Extraction)
增量抽取方式:
- 流抽取:适合小数据集,实时数据采集
- 批量抽取:适合大数据集
适合增量抽取方式的数据,所具有的特性:
- 源数据的数据量较小
- 源数据不易发生变化
- 源数据呈现规律性变化
- 目标数据量巨大
数据转换
数据转换一般包括清洗和转换两部分:
- 首先清洗掉数据集中重复的,不完整的以及错误的数据
- 然后根据具体的业务规则,对数据做转换操作,从而实现数据转换的目的
数据转换基本操作:
- Cleaning:把空值变成“0”或“NULL”,Male 变成 M。
- Deduplication:删除重复数据。
- Data Threshold Validation Check:结合现实世界对数据进行判断,比如年龄不能超过3位数。
- Transpose:行列转置。
数据转换高级操作:
- Filtering:只选取确定的数据加载到数据目的地
- Joining:把多个数据源的数据结合在一起(merge,lookup)
- Splitting:把一列数据分成多列
- Integration:把多列数据整合成一列
在实际业务中,大多数情况下从数据源抽取的数据都经过转换,整合处理后输入到数据目的地中 在实际业务中,也存在高质量的数据,无需经过转换操作,源数据直接到达数据目的地,这种数据叫做Pass Through Data
数据加载
加载是ETL中最后一步,是将已转换后的数据加载到指定的数据仓库中,为后续数据的分析,挖掘提供数据准备
加载两种方式:
- 全量加载(Full Load):
- 全表清空后再进行数据加载
- 从技术角度上来说,比增量加载简单,一般只需要在数据加载之前,清空目标表,再全量导入源表数据即可,但当源数据量较大,业务实时性较高时,大批量的数据无法在短时间内加载成功,此时需要和增量加载结合使用
- 增量加载(Incremental Load):
- 目标表仅更新源表中变化的数据
- 增量加载难度在于更新数据的定位,必须设计明确的规则从数据源中抽取信息发生变化的数据,并将这些变化的数据在完成相应的逻辑转换后更新到数据目的地中
增量加载的方式:
- 系统日志分析方式
- 触发器方式
- 时间戳方式
- 全表比对方式
- 增量数据直接或转换后加载
加载方式好坏的评判标准:
- 可按频率准确的捕获业务系统中的变化数据
- 尽量降低对业务系统造成的压力,及对现有业务的影响
- 能够很好的实现属性映射
- 可快速回复或回滚数据
数据加载需要注意的技术点:
- 缺失值和空值检测
- 目标数据与源数据一致性检测
- 验证已转换数据是否符合预期,即测试数据加载验证
ELT常用工具
ETL注意事项
- 尽量不要清洗全部数据:企业可能存在一次清洗全部数据的现象,但是清洗过多数据会花费较长时间,企业往往没有做好等待全部数据清洗完毕的准备
- 根据实际业务,按需清洗数据,避免数据积压:因为构建数据仓库的最大原因是提供更干净,更可靠的数据
ELT介绍
- 数据抽取,加载和转换简称ELT
- 与ETL的本质区别:在ELT数据管道中,数据被抽取后先加载到数据仓库,然后利用数据库的聚合分析能力或者外部计算框架处理能力对数据进行转换操作
ELT优势
- 简化ETL架构:数据抽取后无需使用单独的转换引擎,数据转换和消耗在同一个地方
- 降低抽取的时间和性能开销:在实际应用中,不同的业务对数据要求存在差异,需要对同一组数据做不同的转换操作,ETL需要多次抽取,转换,加载,而ELT能实现一次抽取,加载,多次转换,实现一份数据多次应用,降低时间和资源开销
常用工具
| DataStage | Kettle | Informatica | |
|---|---|---|---|
| 费用 | 价格昂贵 | 开源 | 费用比DataStage稍低 |
| 易用性 | 有GUI界面 | 有GUI界面 | 有GUI界面 |
| 数据质量 | 有专门的数据质量管理产品ProfileStage和QualityStage | 在GUI里有数据质量管理,通过SQL语句,JAVA脚本,正则表达式进行数据清洗 | 有专门的数据质量产品FirstLogic |
| 源数据支持 | 有专门的源数据管理工具MetaStage | 支持广泛的数据库,数据文件等,同时支持扩展 | 有专门的源数据管理工具Superglue |
除了上述工具以外,还可构建ELT开源数据平台,使用较为广泛的是Kafka Connect,DataX等,也可以直接采用Flink等流式计算框架和Hive代替传统的ETL和ELT工具
数据清洗
数据清洗是指通过删除,转换,组合等方法,处理数据集中的异常样本,为数据建模提供优质数据的过程
缺失值处理
数据缺失原因
在实际业务中,不可避免的会出现数据缺失的现象,总结下来大致有如下几种情形:
- 人为疏忽,机器故障等客观因素导致信息缺失
- 人为刻意隐瞒部分数据,比如在数据表中,有意将一列属性视为空值,此时缺失值就可以看做是一种特殊的特征值
- 数据本身不存在,比如银行做用户信息收集时,对学生群体来说,工资这一属性不存在,因此在数据表里显示为空值
- 系统实时性能要求较高
- 历史局限性导致数据收集不完整
数据缺失的影响
- 机器学习里有一句名言:数据和特征决定了机器学习的上限,而模型和算法的应用只是逼近这个上限。因此高质量的数据对建立好的数据模型有着至关重要的作用。
- 数据集中缺少部分数据可以降低模型过拟合机率,但也存在模型偏差过大的风险,因为没有正确地分析变量的行为和关系,从而导致错误的预测或分类
数据缺失类型
数据集中不含缺失值的变量称为完全变量,数据集中含有缺失值的变量称为不完全变量。数据缺失类型可以分为完全随机缺失,随机缺失和非随机缺失。
- 完全随机缺失 (Missing Completely at Random, MCAR) 对所有数据来说,所有变量的缺失概率都是相同的。数据的缺失不依赖于不完全变量或完全变量。比如,领导通过抛硬币来决定是否公布公司的财务状况。
- 随机缺失 (Missing at Random, MAR) 数据的缺失与其他完全变量有关。比如,收集家庭收入信息这一变量,女性比男性的数据缺失率高。其中性别为完全变量。
数据缺失类型可以分为完全随机缺失,随机缺失和非随机缺失。
- 非随机缺失 (Missing Not at Random, MNAR)
数据的缺失与不完全变量自身的取值有关。MNAP分为两种,分别是:
- 缺失值依赖于未观察变量 数据缺失不是随机的,取决于未观测到的变量。比如,学校开设一门课程,中途退出的人较多,可能与课程内容质量不好有关,但数据集中并未收集“课程质量评分”这一变量。
- 缺失取决于缺失值本身 缺失值的概率与缺失值本身直接相关,比如收入过高或过低的人群不愿意提供自己的收入证明
数据处理的常见方式
数据缺失原因多种多样,针对不同的缺失原因,数据缺失值的处理方式也各不相同。值得注意的是,有时属性缺失并不意味着数据缺失,比如,银行收集客户信息时,学生在“工资”这一栏为空值。缺失本身是包含有价值的信息的。因此要结合具体业务场景、数据场景选择合适的数据缺失值处理方式。 缺失值处理方法众多,总结下来为三种:
- 删除
- 填充
- 不处理
删除
 缺失值操作的Python代码(删除缺失值):
缺失值操作的Python代码(删除缺失值):
import pandas as pd
df = pd.read_csv('wine_old.csv')
df.head()#显示前五行
#缺失值检测
df.isnull().any() #按列进行缺失值检测,一列中有任意位置有缺失值,返回True,否则返回False
df.isnull().sum() #返回每一列中缺失值的数量
df.shape #获取数据的形状
#缺失值占比
df.isnull().sum()/178 * 100
#画柱状图
import missingno as miss
miss.bar(df)
# 缺失值处理----删除
df.dropna(axis=1,how='any',thresh=178 * 0.9,inplace=True)#按列删除,一列中只要有缺失值就删除,删除阈值是90%
#也就是说,完整的值要在这一列中超过90%,这一列才能被保留,inplace表示是否在源数据上操作,如果是True
#表示在源数据上操作,相当于永久修改了,如果是False,则表示在源数据的副本上操作,原数据没变,推荐使用
#False,万一改错了呢
#单独删除列
del df_na['type']
df_na
填充
基于统计学原理,根据初始数据集中非缺失对象取值的分布情况来对一个缺失值进行填充。 填充方式包含人工填充、特殊值填充、平均值填充、热卡填充、KNN、预测模型、组合完整化方法等。 我们主要学习
- 填充
- KNN(还没学)
- 回归(还没学)
- 变量映射(还没学)
填充-Mean/Mode/Median估计
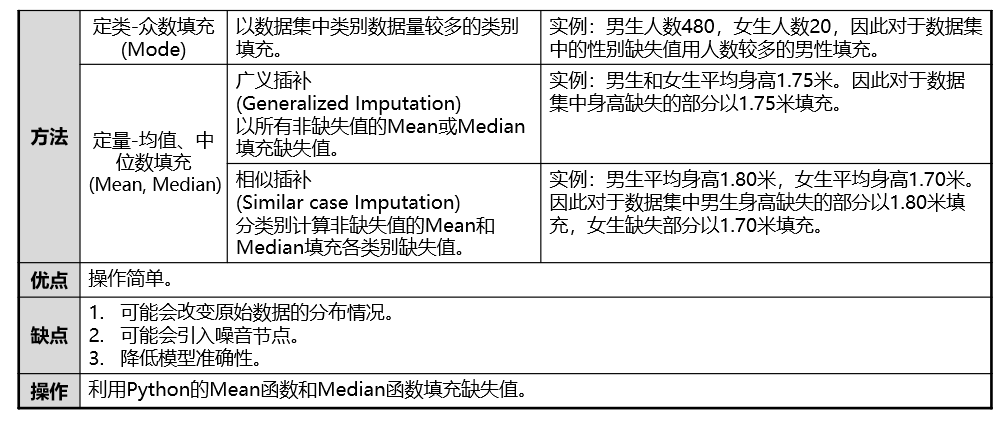
缺失值处理----填充 缺失值的形式:
- 标准,None,NaN
- 特殊,'',' '
替换缺失值: 这部分代码适合于数据中数值型的列和字符串型的列都存在缺失值的情况
# df_na.info()
#查看一列中值的分布
# df_na['malic'].value_counts()
#查看malic这一列的众数
df_na['malic'].mode()
#用malic这一列的一个众数,替换这一列中的空格,因为这一列有一个空值是用空格来表示的,因此这一列为object类型,不能直接算平均数或者中位数,只能先用众数来替换这个空格
df_na['malic'] = df_na['malic'].replace(to_replace=' ',value=df_na['malic'].mode()[0])
#替换完了之后,把整个这一列类型转换成float64,这样这一列就可以计算平均数了
import numpy as np
df_na['malic'] = df_na['malic'].astype(np.float64)
#类型转换完成以后,就可以利用平均数替换其他标准的空值了
df_na['malic'] = df_na['malic'].replace(to_replace=np.nan,value=df_na['malic'].mean())
缺失值填充方法二:只能选择一种填充(均值,众数,中位数)
from sklearn.impute import SimpleImputer
#定义规则(参数)
model_fill = SimpleImputer(missing_values=np.nan,strategy='most_frequent')
#将规则应用到数据上
df_fill = model_fill.fit_transform(df_na)
#转型(将数据转换成DataFrame类型)
df_df = pd.DataFrame(df_fill,columns=df_na.columns)
KNN

回归
- 把数据中不含数据缺失的部分作为训练集,根据训练集建立回归模型。将此回归模型用来预测缺失值并进行填充。
- 此方式只适用于缺失值是连续的情况。比如,北京二手房价缺失值填充。
- 预测填充理论上比值填充效果好,但若缺失值与其他变量没有相关性,则预测出的缺失值数据没有统计学意义
变量映射

不处理
- 补齐的缺失值毕竟不是原始数据,不一定符合客观事实。对数据的填充在一定程度上改变了数据的原始分布,也不排除加入了噪音节点的可能性。
- 因此,对于一些无法应对缺失值的模型,可以用缺失值填充的方式补齐缺失数据。但有些模型本身可以容忍一定的数据缺失情况,此时可以选择不处理的方式,比如Xgboost模型。
异常值处理
异常值是偏离整体样本的观察值,也叫离群点(Qutlier) 异常值会影响数据模型的精确度,因此异常值处理是数据预处理中重要的一步,在实际应用中,研究者可将其用于一些异常检测场景,比如入侵检测,欺诈检测,安全监测等
异常值出现的原因
当异常值出现时,需了解异常出现的原因。针对不同原因,采取不同异常值处理方法,以便达到较好的数据挖掘效果。 异常值出现的原因大致有以下几种:
- 数据输入错误。相关人员无意或故意导致数据异常,比如,客户年收入13万美元,数据登记为130万美元。
- 数据测量、实验误差。此为较常见误差,可因测量仪器不精准导致。
- 数据处理错误。ETL操作不当,发送数据异常。
- 抽样错误。数据采集时包含了错误或无关数据。
- 自然异常值。非人为因素导致的数据异常。比如,根据历史数据预测明年降水量,但今年7月降水量与前五年同期相比大大增加
异常值造成的影响
当出现异常值时,会产生以下几种影响:
- 增加了整体数据方差,降低了统计学检测的权威性。
- 异常值是随机分布,因此可能会改变数据集的正态分布。
- 可能会对回归、ANOVA、T检验等统计学假设的结果产生影响。
异常值检测方法
异常值检测方法较多,本节主要介绍其中四种:散点图、基于分类模型的异常检测、3σ原则及箱型图分析。
- 散点图。将数据用散点图的形式可视化,可观察到异常值。
- 基于分类模型的异常检测
- 根据现有数据建立模型,然后对新数据进行判断从而确实是否偏离,偏离则为异常值。
- 比如,贝叶斯模型、神经网络、SVM等。
- 3σ原则
- 若数据集服从参数为𝜇,𝜎的正态分布或高斯分布,记为𝑋~𝑁(𝜇,𝜎^2)。
- 异常值被定义为,其值与平均值的偏差绝对值超过三倍标准差的值,即P(|x−μ|>3σ)≤0.003
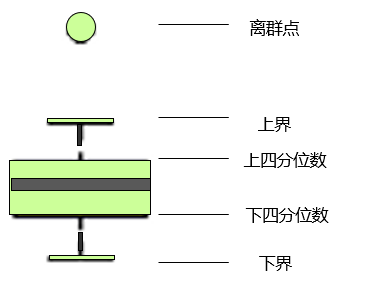
- 箱型图分析-Tukey's test方法
Q1:上四分位数
Q2:下四分位数
IOR:Q1-Q2
最大估计值:
最小估计值:
K代表对异常值的容忍度,一般K=1.5
 异常值检测---箱型图部分代码
异常值检测---箱型图部分代码
sfw = df_na['ash'].describe()
#获取上四分位数
Q1 = sfw["75%"]
# 获取下四分位数
Q2 = sfw["25%"]
#获取IOR
IOR = Q1 - Q2
for x in df_na['ash']:
if x > Q1 + 1.5 * IOR or x < Q2 - 1.5 * IOR:
print(x)
异常值检测---3σ原则
import numpy as np
#计算平均数
mean = df_na['ash'].mean()
#计算标准差
std = np.std(df_na['ash'])
for x in df_na['ash']:
#判断该列中的每个值与平均值的差的绝对值是否大于3倍标准差
if np.abs(x - mean) > 3 * std:
print(x)
异常值的处理方法
- 删除异常值。适用于异常值较少的情况。
- 将异常值视为缺失值,按照缺失值处理方法来处理异常值。
- 估算异常值。Mean/Mode/Median估计数据填充异常值。 异常值处理部分代码--->填充,箱型图
#接上一段代码,x为发现的异常值,用平均数替换x,就在原数据上改
df_na['ash'].replace(x,value=df_na['ash'].mean(),inplace=True)
#绘制箱型图
import matplotlib.pyplot as plt
plt.boxplot(df_na['ash'])
特征处理
特征工程是通过对原始数据处理和加工,将原始数据的属性转换为数据特征的过程。特征工程涵盖很多方面,其中较重要的部分是特征处理和特征选择。
特征缩放
特征缩放的必要性
案例引入 假设住房价格受住房面积和卧室数量的影响。基于此假设,研究人员可用住房面积和卧室数量这两个参数预测房价。已知住房面积范围在[100,400](平方米),卧室数量范围在[2,4](间)。由此可见,住房面积这一属性值域范围较大,在建立相关模型预测房价时可能会出现仅住房面积这一属性就可预测出房价的现象,弱化了其他属性在数据模型中的作用,造成一定的预测误差。 必要性
- 在实际业务中,当数据的量纲不同,数量级别差距大时,会影响最终的数据模型,因此需用特征缩放来平衡各特征贡献。
- 特征缩放可提高模型精度和模型收敛速度。它是数据预处理的重要环节之一。特征缩放又叫数据归一化。
特征缩放的方法概览
- 标准化(Standardization)
- 最小值-最大值归一化(Min-Max Normalization)
- 均值归一化(Mean Normalization)
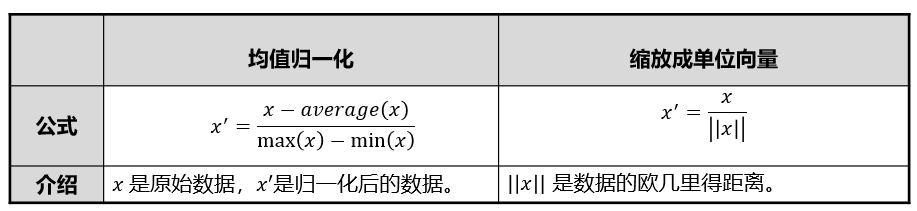
- 缩放成向量单位(Scaling to Unit Length)
特征缩放-标准化
标准化是将训练集中的某一列 (特征) 缩放成均值为0,方差为1的状态。对特征向量进行缩放是无意义的,比如对班级、年龄、性别一组特征向量 (行) 进行标准化操作是无价值的。标准化要求原始数据近似满足高斯分布,数据越接近高斯分布,标准化效果越佳
x'=\frac{x-\mu}{\sigma}
特点
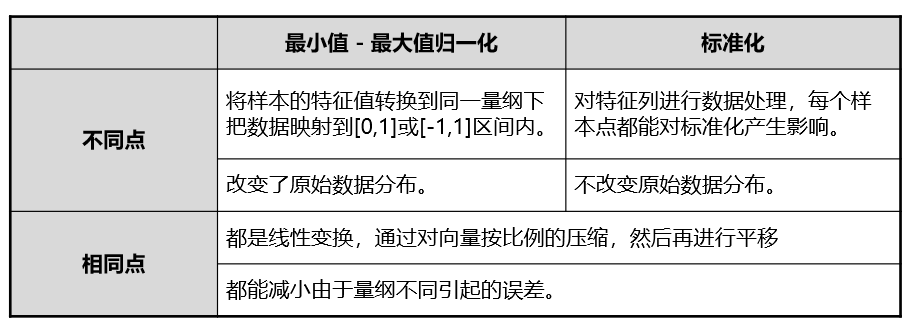
- 标准化后使得不同度量的数据特征具有可比性,同时不改变数据的原始分布状态。
- 标准化对数据进行规范化处理,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权 特征标准化代码:
from sklearn.preprocessing import StandardScaler
#定义规则
model_ss = StandardScaler()
#应用到数据上
df_ss = model_ss.fit_transform(df_na[[col for col in df_na.columns if col != "type"]])
#类型转换
df_ss = pd.DataFrame(df_ss,columns=[col for col in df_na.columns if col != "type"])
df_ss
运行结果: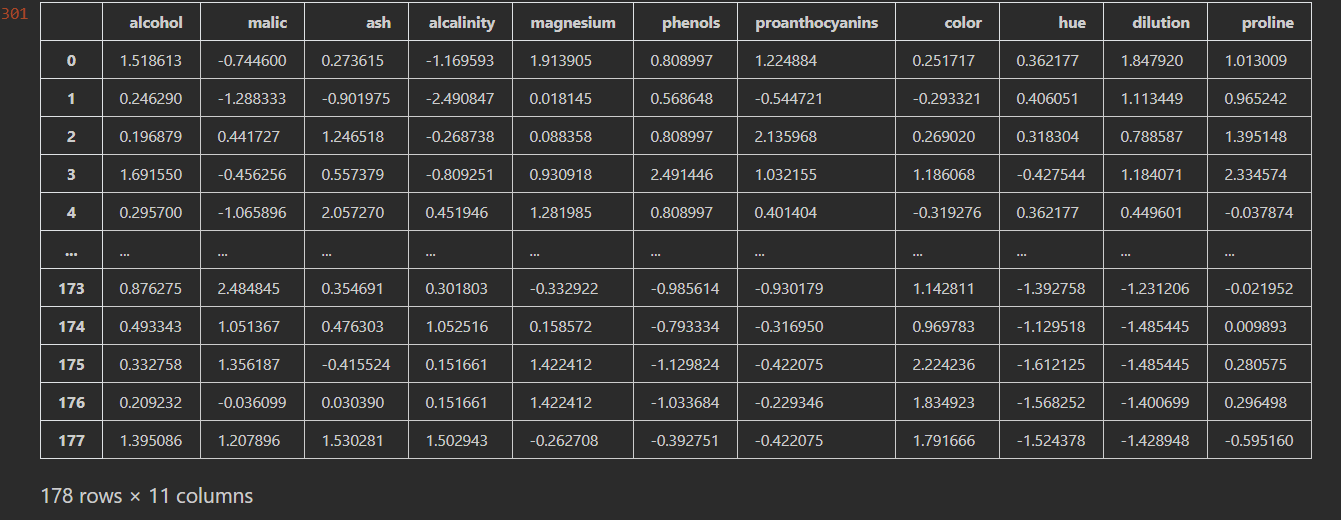
最小值-最大值归一化
定义:将训练集中某一列特征数值缩放到0-1或者-1-1之间
x'=\frac{x-min(x)}{max(x)-min(x)}
特点:
- 受训练集中最大值和最小值影响大,存在数据集中最大值与最小值动态变化的可能
- 容易受噪声(异常点,离群点)影响 最小值-最大值归一化部分代码:
from sklearn.preprocessing import MinMaxScaler
#设置归一化范围是[-1,1],默认是[0,1]
model_mm = MinMaxScaler(feature_range=(-1,1))
df_mm = model_mm.fit_transform(df_na[[col for col in df_na.columns if col != 'type']])
df_mm = pd.DataFrame(data=df_mm,columns=[col for col in df_na.columns if col != 'type'])
df_mm
运行结果:
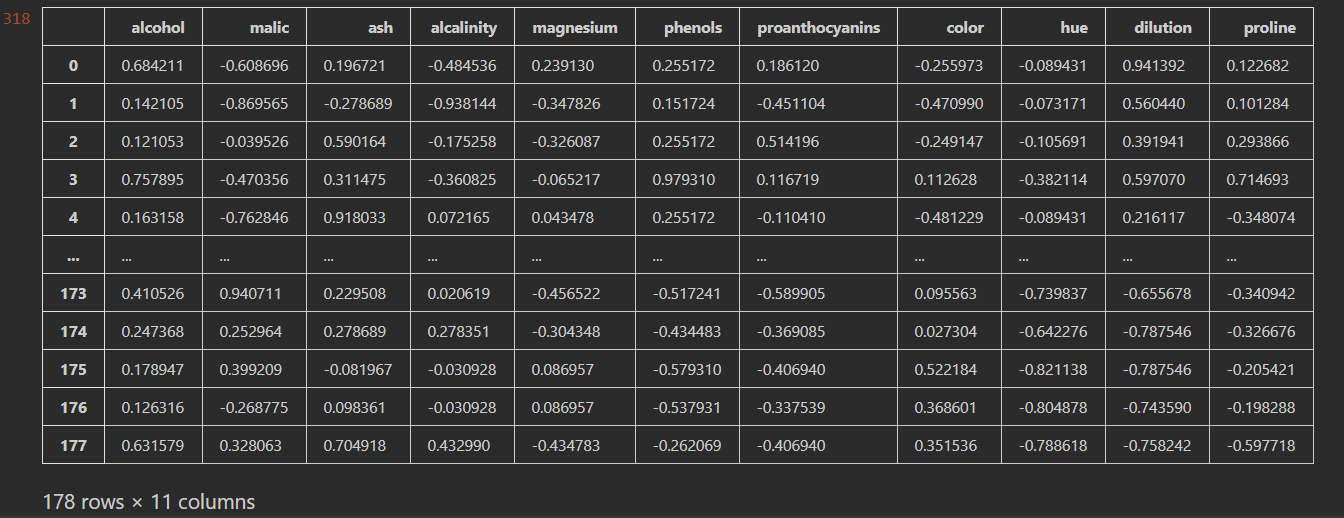
特征缩放的优点
提升模型精度 在多属性指标模型中,不同的属性可能会有较大的取值差距,比如属性一取值范围[10000,3000000],属性二取值范围[10,30]。如果直接用原始数据进行分析,可能会造成属性一对最终模型影响较大,相对弱化属性二指标的作用。因此,为保证结果可靠性,需对原始数据进行特征缩放操作。在涉及到距离计算时效果较明显。 提升收敛速度 对于线性模型来说,特征缩放后,最优解的寻优过程会变得平缓,更容易收敛到最优解
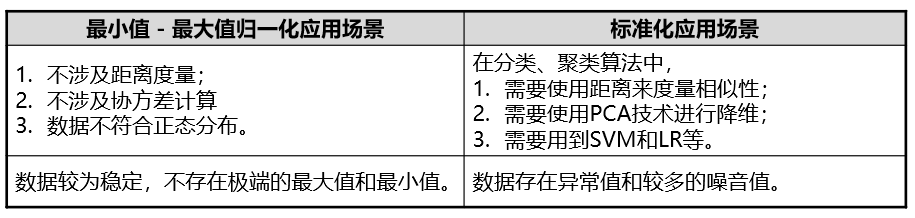
特征缩放的应用场景
标准化和最小值-最大值归一化的区别
特征缩放的其他方法
数值离散化
- 百度词条把数据离散化定义为把无限空间中有限的个体映射到有限的空间中去,以提高算法的时空效率。换句话说,在不改变数据相对大小的情况下,对数据进行相应缩小。
- 离散化仅适用于只关注元素之间的大小关系而不关注元素数值本身的情况
- 数值离散化在数据预处理中发挥重要作用。离散化可以降低特征中的噪声节点,提升特征的表达能力。但在实际应用中要根据不同环境和不同数据,选择合适的数值离散化方法。
数值离散化的必要性
- 在数据挖掘理论研究中,数值离散化对数据预处理影响重大。研究表明离散化数值在提高建模速度和提高模型精度上有显著作用。
- 比如,对于决策树来说,离散化数据可以加快数据建模的速度,拥有更高的模型精度;离散化数值后,简化了逻辑回归,降低了数据过拟合的风险。
- 数值离散化实际是一个数据简化机制。因为通过数值离散化过程,一个完整的数据集变成一个个按照某种规则分类的子集,增强了模型的稳定性。
- 比如,30-40为一个年龄区间,标记为Mature。这样就可以避免从30岁到31岁就变成了另一类群体人员
- 离散化后的特征对异常数据有很强的鲁棒性。能减少噪音节点对数据的影响。
- 比如,如果规定满分值中成绩大于80分为A,小于80分为B,则出现异常值120会被标记为A,减低了异常值对模型的干扰。
- 某些算法只能处理离散化数据,但即使模型可以处理连续型数据,其综合学习效率和模型精度也要稍逊色于离散化数据。 注意:任何离散化过程都会带来一定的信息丢失,因此寻求最小化信息丢失是使用数值离散化技术人员的核心目标之一
连续变量的离散化
- 连续变量的离散化分为有监督和无监督两类。
- 连续变量的离散化过程分为四个核心步骤:
- Sorting: 对连续型变量进行排序,为离散化做准备。
- Evaluating: 对Splitting来说评估分割点(自顶向下),对Merging来说评估合并点(自底向上)。
- Splitting or Merging: 分割或合并区间。
- Stopping: 达到停止条件,停止离散化。
连续变量的离散化过程步骤详解
- Sorting
- 对连续型变量升序或降序。尽量选择时间复杂度低的排序算法,优选时间复杂度为O(NlogN) 。
- Evaluating
- 排序完成后,要选择较佳的分割点或合并点。自顶向下是划分间隔,自底向上是合并间隔。
- 评估较佳分割点或合并点的策略是评价函数,比如,熵测量、均方根误差 (RMSE)、平均绝对百分误差 (MAPE)等 ,以此判断分割或合并后的模型的Performance是否提升,提升保留,否则舍弃。
- Sorting
- 对连续型变量升序或降序。尽量选择时间复杂度低的排序算法,优选时间复杂度为O(NlogN) 。
- Evaluating
- 排序完成后,要选择较佳的分割点或合并点。自顶向下是划分间隔,自底向上是合并间隔。
- 评估较佳分割点或合并点的策略是评价函数,比如,熵测量、均方根误差 (RMSE)、平均绝对百分误差 (MAPE)等 ,以此判断分割或合并后的模型的Performance是否提升,提升保留,否则舍弃。
无监督连续变量的离散化
聚类划分
- 使用聚类算法将数据分为K类,需要制定K值大小。
- 把同属一类的数值标记为相同标签。
- 可运用Kmeans算法对数据进行聚类划分。
- 受K的选择影响大。K过大、过小都会影响聚类结果。 解决方案
- 合理选择K的大小(如何选择K值后续章节详细讲解)。 实现
- Python里Kmeans方法。
分箱 - 等宽划分
- 把连续变量按照相同的区间间隔划分几等份。换句话说,根据连续变量的最大值和最小值,划分N份,每份数值间隔相同。 划分区间间隔
- 一组连续数值,最大值20,最小值1,划分为4份。划分后结果为[1,5],[6,10],[11,15],[16.20]。
- 受异常点影响大。极端情况下若上述19个数值在1至5之间,剩余一个为20。会导致数据全部集中在[1,5]。
- 设置阀值,检测异常值。
- Python里pandas.cut方法。 等宽离散化的代码部分:
import pandas as pd
df = pd.read_csv('wine_old.csv')
#利用cut方法,将数据等宽的离散成3份,分别赋予标签
df['proline'] = pd.cut(df['proline'],3,labels=['low','middle','high'])
df.head()
运行结果:

分箱 - 等频划分
- 把连续变量划分几等份,保证每份的数值个数相同。具体来说,假设共有M个数值,划分N份,每份包含个数值。划分个数。
- 一组连续数值10个(11,12,12,12,13,14,15,16,17,18),划分为5份。划分后结果为[11,12],[12,12],[13,14],[15,16],[17,18]。
- 会出现相同数值被划分到不同区间。
- 划分完成后进行微调。
- Python里pandas.qcut方法。
等频离散化的代码部分
import pandas as pd
df = pd.read_csv('wine_old.csv')
df['alcohol'] = pd.qcut(df['alcohol'],3,labels=['low','middle','high'])
df.head()
有监督连续变量的离散化
1R
- 有监督的分箱方法。把连续的区间分成小区间,然后根据类标签对区间内变量调整。每个区间至少包含6个变量(最后一个区间除外)。
- 无需人为制定箱的个数,避免了无监督等宽和等频方法的缺陷。
- 通过1R算法实现。
- 步骤:
- 从第一个变量开始,将前N个变量纳入第一个区间。N一般取6。
- 若第七个变量的类别标签与第一个区间内的大多数变量的类别标签相同,则把第七个变量纳入第一个区间,然后按此方法继续判断第八个变量。
- 若第七个实例的类别标签与第一个区间内的大多数变量的类别标签不相同,则从第七个实例开始纳入六个变量,建立第二区间。
- 然后对后续变量按照相同的方法判断是否属于第二区间,直至结束。
- 最终根据每个区间中的大多数变量的共同标签决定这个区间的标签。
- 通过此流程,对各区间添加标签后,可能会出现相邻区间类别标签相同的情况,此时合并相邻区间。
基于信息熵的方法
- 自顶向下的方法,运用决策树的理念进行变量离散化。
- 因涉及到具体算法决策树的相关内容(后续详细介绍),因此在此仅简要说明。
- 步骤
- 计算数据集中每个变量的熵,选择熵值最小的点作为端点,将数据集一分为二。再利用递归的方式继续对每个小区间的数值一分为二。直到满足停止条件。
- 停止条件有:每个区间实例小于14个等等。
- 根据最小描述长度准则 (MDLP) 衡量哪些是符合要求的端点,哪些不是。对不符合要求的端点进行合并。
基于卡方的方法
- 自底向上的方法,运用卡方检验的策略,自底向上合并数值进行有监督离散化,核心操作是Merge。
- 将数据集里的数值当做单独区间,递归找出可合并的最佳临近区间。判断可合并区间用到卡方统计量来检测两个区间的相关性,对符合所设定阀值的区间进行合并。
特征编码
数据挖掘中,一些算法可以直接计算分类变量,比如决策树模型。但许多机器学习算法不能直接处理分类变量,它们的输入和输出都是数值型数据。因此,把分类变量转换成数值型数据是必要的,可以用独热编码 (One-Hot Encoding) 和哑编码 (Dummy Encoding)实现。 比较常用的是对逻辑回归中的连续变量做离散化处理,然后对离散特征进行独热编码 (One-Hot Encoding) 或哑编码 (Dummy Encoding),这样会使模型具有较强的非线性能力。
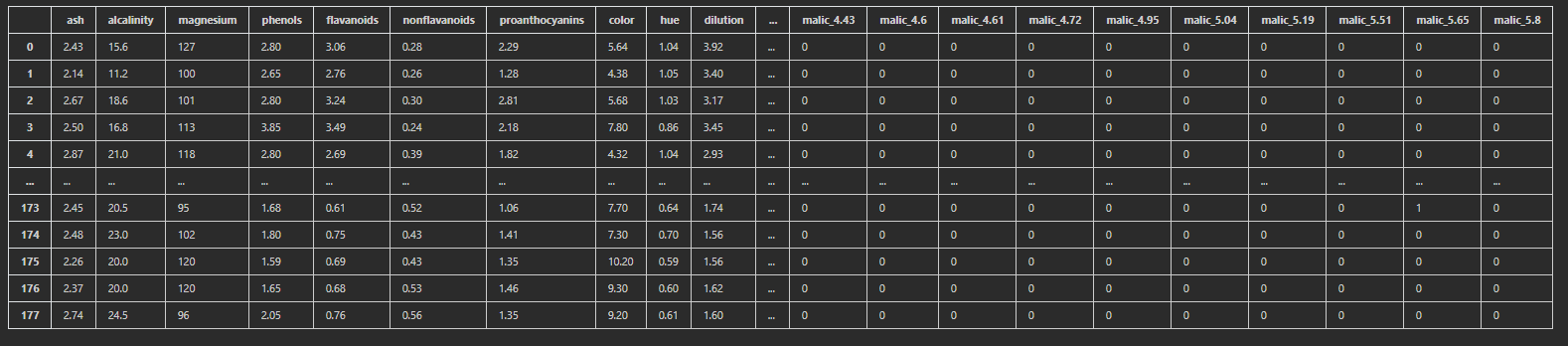
独热编码(One-Hot Encoding)
使用M位状态寄存器对M个状态进行编码,每个状态都有独立的寄存器位,这些特征互斥,所以在任意时候只有一位有效。也就是说,这M种状态中只有一个状态位值为1,其他状态位都是0。换句话说,M个变量用M维表示,每个维度的数值或为1,或为0 独热编码的代码部分:
import pandas as pd
df = pd.read_csv('wine_old.csv')
df['alcohol'] = pd.qcut(df['alcohol'],3,labels=['low','middle','high'])
df_oh = pd.get_dummies(df)
df_oh
运行结果:
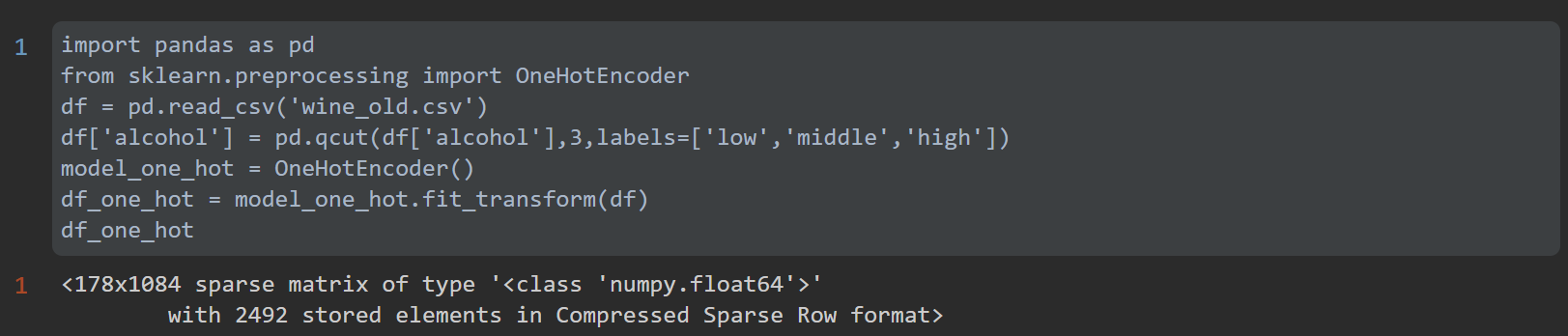
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
df = pd.read_csv('wine_old.csv')
df['alcohol'] = pd.qcut(df['alcohol'],3,labels=['low','middle','high'])
model_one_hot = OneHotEncoder()
df_one_hot = model_one_hot.fit_transform(df)
df_one_hot
运行结果:
哑编码(Dummy Encoding)
哑编码和独热编码很相似,唯一的区别在于哑编码使用M-1位状态寄存器对M个状态进行编码
Label-Encoding
有序分类变量数值之间存在一定的顺序关系,可直接使用划分后的数值进行数据建模。 如分类变量{低年级,中年级,高年级},可以直接离散化为{0,1,2}。 在Python中可以用pandas库中的map函数实现有序分类变量的离散化。 Label-Encoding部分代码:
import pandas as pd
df = pd.read_csv('wine_old.csv')
df['alcohol'] = pd.qcut(df['alcohol'],3,labels=['low','middle','high'])
df['alcohol'] = df['alcohol'].map({'low':0,'middle':1,'high':2})
df.head()
运行结果:

时间数值转换
在实际业务中,时间数据是经常用到的数据信息。在数据预处理中可能存在 日期格式 - 字符串格式 - 数值格式之间的相互转换。 Python中常用的datetime模块解决大多数日期和时间的处理问题。若需解决更复杂的时间问题,比如:日期计算,可用dateutil模块。
不均衡数据处理
类别数据不均衡是分类任务中存在的经典问题,一般在数据清洗环节进行处理。不均衡简单来说,在数据集中,一类样本的数据量明显远大于其它样本类别数据量。比如,在1000条用户数据中,男性数据有950条,女性数据只有50条
不均衡数据的影响
- 一般而言,若数据类别比例超过4:1,即认为数据集中存在不均衡数据的现象。
- 因分类器会受不均衡数据的影响,所以对部分数据建模任务来说,数据集中若存在不均衡数据会影响最终的模型分类效果,从而无法满足分类要求。
- 对部分数据建模任务来说,数据集中存在不均衡数据是符合研究人员期望的。比如,银行收集客户欺诈行为数据。对于大部分客户来说,其在银行交易中不存在欺诈行为,只有少部分客户数据存在异常。针对此类现象,可以用异常检测模型理念分析数据。
不均衡数据的处理
重新采样数据 重采样是不均衡数据处理的常用方法之一,其分为欠采样和过采样两种方法。以下将数据量大的数据类别定义为丰富类,数据量少的数据类别定义为稀有类。
欠采样
适用于大数据集,从丰富类中随机选择少量样本,再合并原有稀有类作为新的训练数据集。
过采样
适用于小数据集,从稀有类中随机选择样本,再合并原有丰富类作为新的训练数据集。 方法 Python中SMOTE算法。
K-Fold交叉验证
将数据集分为K份,(K-1)份为训练集,其余为测试集。计算K次后取其平均值。

一分类
适用于数据集样本分布极其不平衡的现象。当遇到此类情况时,可转换为异常检测问题或一分类问题。典型运用:one class SVM (后续章节详细讲解SVM)。 组合不同的重采样数据集 核心原理:建立N个模型。 假设存在100个稀有数据,则从丰富类中随机抽样出1000 (100*10) 个数据。将这1000个数据分成N份,分别和100个稀有数据合并建立模型。
本文章使用limfx的vscode插件快速发布