20220624 强化学习笔记
马尔可夫决策过程
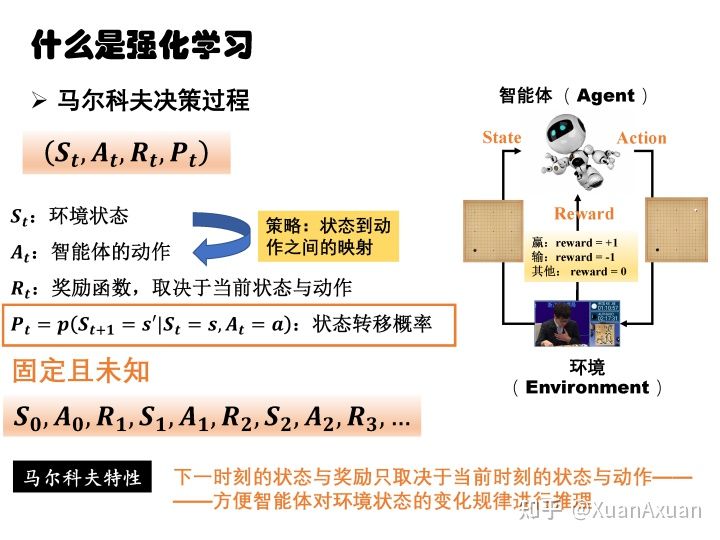
通过最大化reward得到一个最优策略。
如果只考虑即时reward就成了贪心策略,因此还要考虑未来的reward。
因此构造了值函数(value function)描述这个变量
值函数
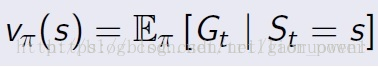
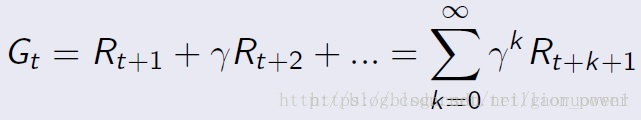
折扣系数用于描述未来的reward对当前动作的影响。一般越靠近当前的反馈越重要。
模型
用于预测在当前这个状态下执行某个动作会达到什么状态以及这个动作能得到什么reward。

总结
状态空间S(一个有限集合)+ 动作空间A(一个有限集合)+ 状态转移概率矩阵P + 奖励函数R
Bellman方程
回报
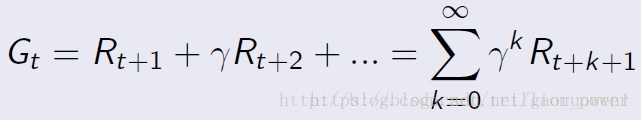
t时刻未来执行一组action后能够得到的reward之和。
状态值函数Value function v(s)
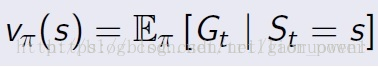
t时刻状态S能够获得的reward的期望。
动作值函数Action-Value function

t时刻状态S下进行特定action后能够获得的reward的期望。
Bellman方程
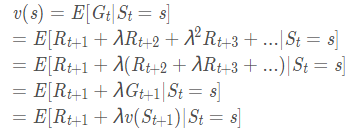
说明状态值函数是可以通过迭代计算的。
同理有动作值函数
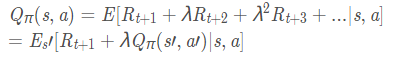
强化学习是怎么执行的?
根据Q(s, a)函数,判断s状态下采取哪个action得到的Q期望最大。
目标
需要最优策略,等价于求解最优的action-value function。
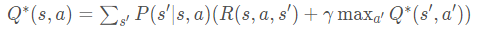
怎么做?
Q-Learning
适用于离散状态、离散行为模型。
因为这个例子中某个状态s下采取a行为后过渡到的状态是确定的,所以P(s'|s,a) = 1,只存在一个s’
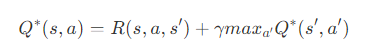
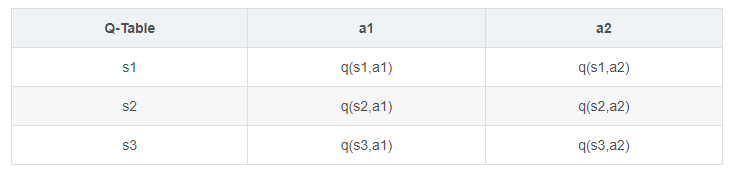
根据这个表,在某个状态s,找到Q值最大的那个action并执行。
迭代公式

其中alpha为学习率。s’表示在s状态执行a后过渡到的新状态s‘。
后一项表示估计的新Q值和实际的Q值的差距。
Deep Q Learning
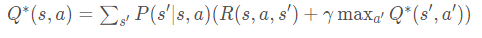
具体还没看。大概意思应该是训练出一个模型,输入参数是当前的s,结果是一个action。
DQN正向计算得到所有控制动作的预测Q值,将目标Q值和预测Q值的均方差定义为损失函数,根据损失函数梯度下降更新网络参数。

电网
state:节点电压、有功、无功,分布式电源出力、负荷水平、线路功率等
action:分布式电源输出功率、可控负荷功率、节点调压、发电功率等
reward:电压越限、发电成本、消纳率、线损等
本文章使用limfx的vscode插件快速发布