WEEK2
#PART1 ##Merkle Tree 哈希列表 Hash List(前提):
在去中心化网络,或者叫点对点网络上,数据往往都是拆分成很多小碎片去下载的,而且其中很多机器可以认为是不稳定或者是不可信的,这时需要有更加巧妙的做法。最简单的方式就是用 Hash List ,也就是哈希列表。
实际中,点对点网络在传输数据的时候,其实都是把比较大的一个文件,切成小的数据块。这样的好处是,如果有一个小块数据在传输过程中损坏了,只要重新下载这一个数据块就行了,不用重新下载整个文件。当然这就要求对每个数据块计算哈希值,所有这些小数据块的哈希值都是兄弟关系,这样就组成了一个哈希列表。BT 下载的时候,在下载真正的数据之前,会先下载一个哈希列表的,这个就是所谓的种子文件。有了各个 hash 之后,数据本身就可以从任意的机器上下载了,不用管那些机器是否是安全可信的。

把每个小块的哈希值拼到一起,然后对整个这个长长的字符串再做一次哈希运算,最终的结果就是哈希列表的根哈希。
Merkle Tree 哈希树:

在最底层,和哈希列表一样,数据分成小的数据块,有相应的哈希和它对应。但是往上走,并不是直接去运算根哈希,而是把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,这样每两个哈希就得到了一个”子哈希“。如果最底层的哈希总数是单数,那到最后必然出现一个单身哈希,这种情况就直接对它进行哈希运算,所以也能得到它的子哈希。于是往上推,依然是一样的方式,可以得到数目更少的新一级哈希,最终必然形成一棵倒挂的树,到了树根的这个位置,这一代就剩下一个根哈希了,叫做 Merkle Root 。
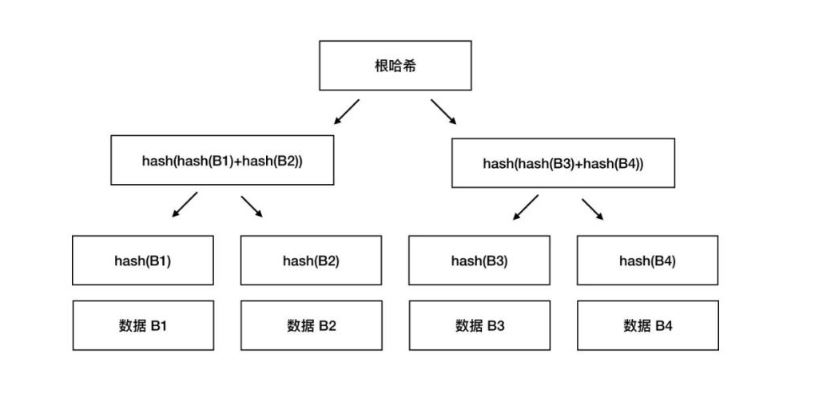
Merkle Tree 本身也算是一个哈希列表,只不过是在这个基础上又引入了树形结构,从而获得了更高的灵活性。
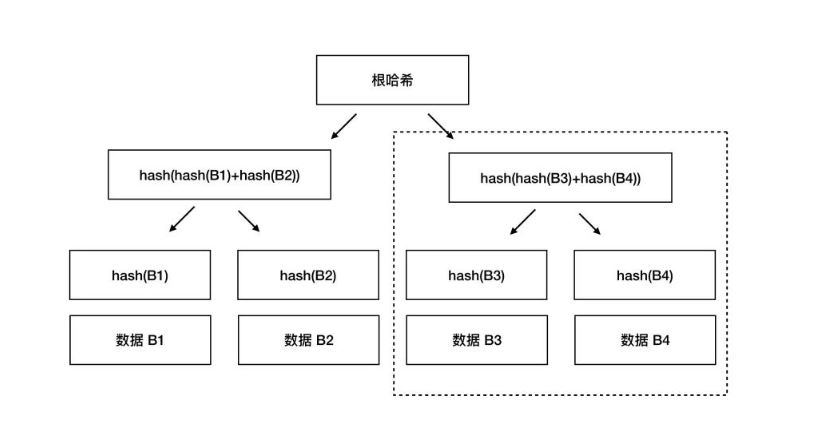
Merkle Tree 是三个概念的叠加,一个是哈希,第二个是哈希列表,第三个是树。
##PART2 ###共识协议 去中心化需要解决的问题问题:
1.货币该由谁发行?在比特币中是由挖矿来解决。
2.怎样验证有效性,防止double spending attack?
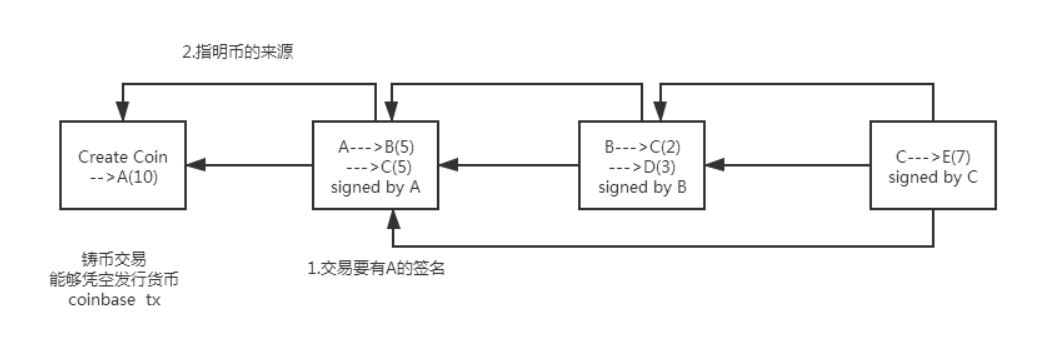
比特币交易中包含输入和输出两部分,输入部分要说明币的类型以及付款的公钥,输出部分要给出收款的公钥的哈希。
转账交易要说明花掉的币从哪来的:1.防止币是凭空捏造的 2.防止double spending attack.
转账交易(A-->B)需要的信息:A的签名,B的地址。
A需要知道B的地址,比特币中收款地址是通过公钥推算出来的,地址相当于银行账号,而公钥是可以公开的,不需要保密。
B需要知道A的公钥,大家都需要知道,代表A的身份,用来验签。
A--->B交易中A的公钥要与币的来源中A的公钥的哈希对得上。如果此时有B’伪造一对公私钥,冒充A给B转账,虽然B'的公钥能够验签成功,但是该公钥与币的来源中公钥的哈希值对不上,所以无法伪造交易。
图中一个简化假设是每一个区块只有一个交易,实际系统中每个区块可以包含很多笔交易,这些交易组织成merkle tree。每个区块分成块头 Block header和块身 Block body两部分。
协议主体
某个节点打包交易到区块,将其发给其他节点,其他节点检查该候选区块,检查若正确投赞成票,若票数过半,加入区块链。出现问题:
1:恶意节点不断打包不合法区块,导致一直无法达成共识。
2:无强迫投票手段,某些节点不投票。
3:网络延迟事先未知,投票时间未知。
4:比特币系统,任何人都可以加入,且创建账户及其简单,只需要本地产生公私钥对即可。只有转账(交易)时候,比特币系统才能知道该账户的存在。这样,黑客可以使用计算机专门生成大量公私钥对,当其产生大量公私钥对超过系统中一半数目,就可以获得支配地位(女巫攻击)。
比特币系统中依据算力进行投票。
在比特币系统中,每个节点都可以自行组装一个候选区块,而后,尝试各种nonce值,这就是挖矿。 当某个节点找到符合要求的nonce,便获得了记账权,从而可以将区块发布到系统中。其他节点受到区块后,验证区块合法性,如果系统中绝大多数节点验证通过,则接收该区块为最新的区块并加入到区块链中。
分叉情况
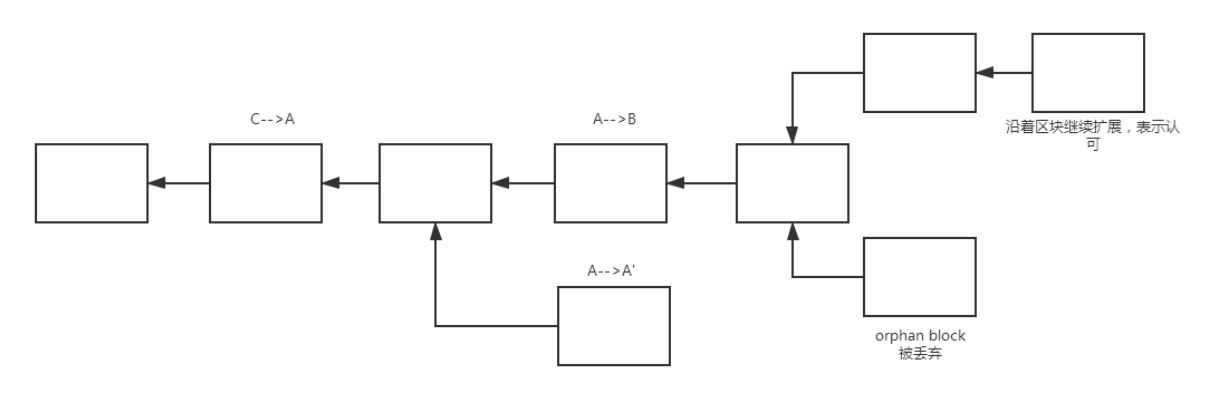
A-->A'的区块中包含的交易都是合法的,但是插在了区块链中间,比如A先把钱转给了B,又把钱转给了自己A',这个交易是合法的,不属于double spending(验证double spending是从当前区块到币的来源之间,中间的区块是否有花过这些币)。A-->A'是想把A-->B的交易回滚掉,把钱再转给自己,虽然交易合法,但是不在最长合法链 longest valid chain中,上面的链才是最长合法链。所以在比特币中,接收的区块应该是在最长合法链中。A-->A'例子其实是分叉攻击 forking attack,通过往区块链中间位置插入区块,来回滚某个已经发生过的交易。
正常情况下也会出现分叉,比如两个节点同时获得记账权,这时候会出现两个等长的分叉,如图后半部分的分叉,此时这两个都属于最长合法链。如果出现系统中两个节点同时发布区块,这种等长的,临时性的区块会维持一段时间,直到某一个分叉最后胜出,另一个被丢弃,叫做orphan block。
#PART3 ##基于交易的账本模式 区块链是一个去中心化的账本,比特币采用了基于交易的账本模式。然而,系统中并无显示记录账户包含比特币数,实际上其需要通过交易记录进行推算。在比特币系统中,全节点需要维护一个名为 UTXO(Unspent Transaction Output尚未被花掉的交易输出) 的数据结构。
UTXO集合中每个元素要给出产生这个输出的交易的哈希值,以及其在交易中是第几个输出。通过这两个信息,便可以定位到UTXO中的输出。
目标:防止double spending。判断一个交易是否合法,要查一下想要花掉的BTC是否在该集合中,只有在集合中才是合法的。如果想要花掉的BTC不在UTXO中,那么说明这个BTC要么根本不存在,要么已经被花过。所以,全节点需要在内存中维护一个UTXO,从而便于快速检测。
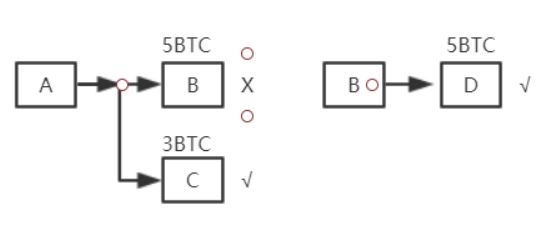
A转给B5个BTC,之后B将其转给D,则UTXO中会删掉A->B这一交易记录,同时会添加B->D这一交易记录。
基于交易的模式与基于账户的模式
比特币是基于交易的模式,与之对应,还有一种基于账户的模式(如:以太坊)。基于账户的模式要求系统中显示记录账户余额。比特币这种模式,隐私性较好,但其也付出一定代价。在进行交易时,因为没有账户这一概念,无法知道账户剩余多少BTC,所以必须说明币的来源(防止双花攻击)。而基于账户的模式,则避免了这种缺陷。
##挖矿过程的概率分析
挖矿本质上可以视为一次伯努利试验。最典型的伯努利试验就是投掷硬币,正面和反面朝上概率为p和1-p。在挖矿过程中,一次伯努利试验,成功的概率极小,失败的概率极大。挖矿便是多次进行伯努利试验,且每次随机。这些伯努利试验便构成了a sequence of independent Bernoulli trials(一系列独立的伯努利试验)。
对于挖矿来说,便是多次伯努利试验,最终找到一个符合要求的结果。在这种情况下,可以采用泊松分布进行近似,由此通过概率论可以推断出,系统出块时间服从指数分布。
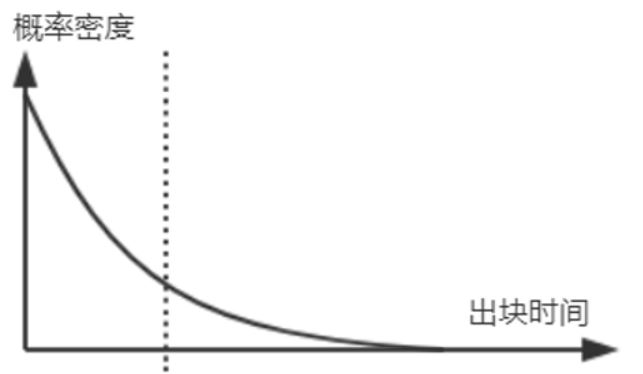
比特币将区块间隔设计为10分钟,是在更快速的交易确认和更低的分叉概率间作出的妥协。更短的区块产生间隔会让交易确认更快地完成,也会导致更加频繁地区块链分叉。与之相对地,长的间隔会减少分叉数量,却会导致更长的确认时间。
EG:
比特币越来越难被挖到,且出块奖励越来越少,是否说明其未来挖矿的动力将越来越低呢?
实际上,恰恰相反。在早期比特币很容易挖到的时候,比特币并不被人们所看好,而后,比特币估值上涨,吸引其他人参与挖矿,又进一步促进了比特币价值上涨,进而又吸引更多人参与进来。当出块奖励趋于0时,则整个系统将依赖于交易费运行,届时交易费将成为维护比特币系统运行的重要保障。
#PART4
##所在网络的工作原理
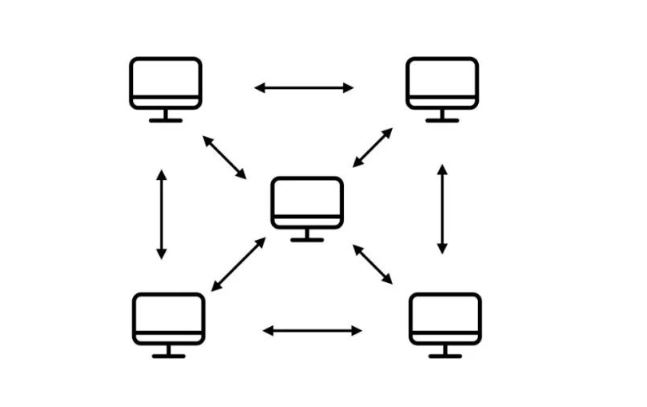
比特币工作于网络应用层,其底层(网络层)是一个P2P Overlay network(P2P覆盖网络)。比特币系统中所有节点完全平等,不像一些其他网络存在超级节点(super node)。要加入网络,至少需要知道一个种子节点,通过种子节点告知自己它所知道的节点。节点之间的通信采用了TCP协议,便于穿透防火墙。当节点离开时,只需要自行退出即可,其他节点在一定时间后仍然没有收到该节点消息,便会将其删掉。
每个节点维护一个邻居节点集合,消息传播在网络中采用洪泛法,某个节点在收到一条消息会将其发送给所有邻居节点并标记,下次再收到便不会再发送该消息。邻居节点选取随机,未考虑网络底层拓扑结构,也与现实世界物理地址无关。该网络具有极强的鲁棒性,但牺牲了网络效率。
假如某个节点先听到A->B,但又听到A->C已经上链,则此时A->B为非法交易,所以要在等待上链交易集合中删除A->B(时效性),且区块大小越大,网络上传播时延越长;区块大小越小,则可以包含的交易数目越少。
本文章使用limfx的vscode插件快速发布