Progress Report and Working Schedule
1. 乌鞘岭数据overview
新数据有三个站点,分别是乌鞘岭、武威和永昌。记录的时间为2010年-2017年,采样频率6h一次。从时间序列上看数据是比较完整的,八年累计数据22278条,没有时间上的缺测。共计特征20个,其中包含六小时累计降雨(label)。
但乌鞘岭数据的缺测非常严重。无论采取回归还是分类做该地区的降雨,只能用“六小时降雨”做为label或处理之作为label。单做降雨量的overview是这样的:
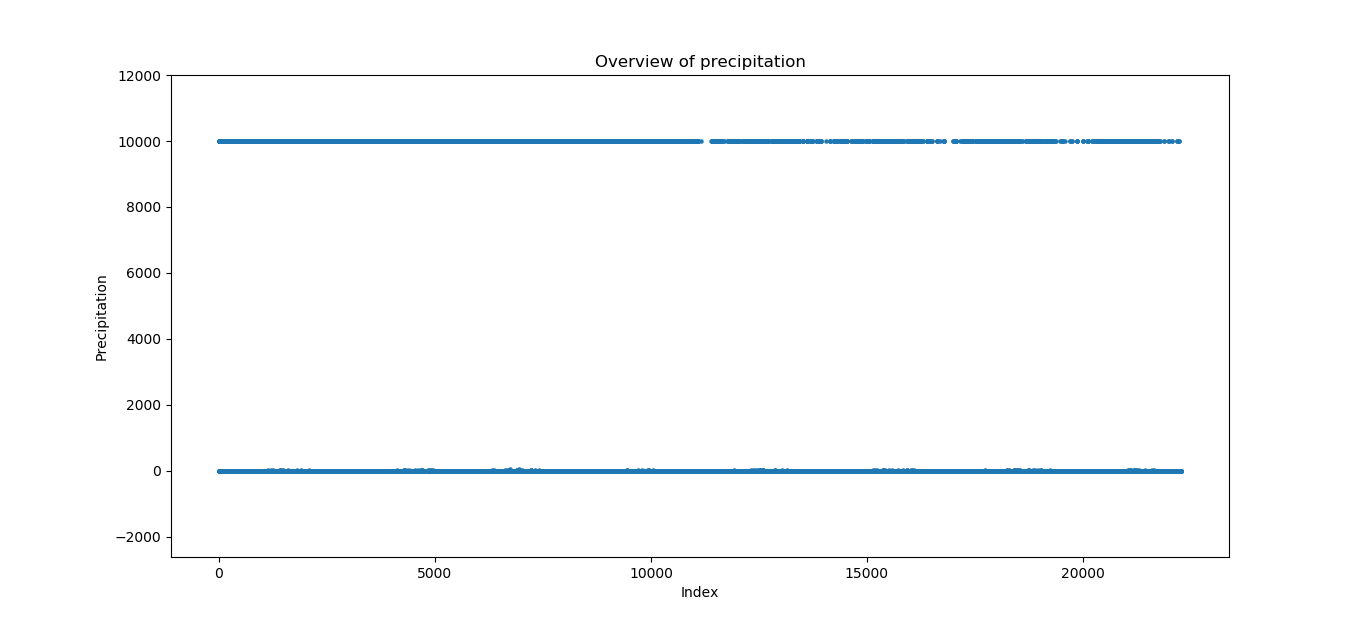
缺测(9999)比较均衡的分布在全部时间区间内。这些值我们只能去除掉,没有降雨量其他特征是没有意义的。经过初步的筛选与处理,剩余了14857/22278条数据(乌鞘岭)。
2. Regional regression attempt
在六盘山所做的区域回归还是比较不错的,因此我试图把方法迁移过来,利用两个站点的雨量试图找出目标站点的关系。然而,由于这个地区的雨量比六盘山的小很多,同时由于数据特征,六盘山的缺测属大范围缺测,在我利用的数据中几乎没有缺测,因此可以进行合并雨量和特征的操作,增大雨量的值。但乌鞘岭的数据由于缺测分布平均,进行雨量的合并是不科学的。也不能单纯的把缺测量换成0再合并。
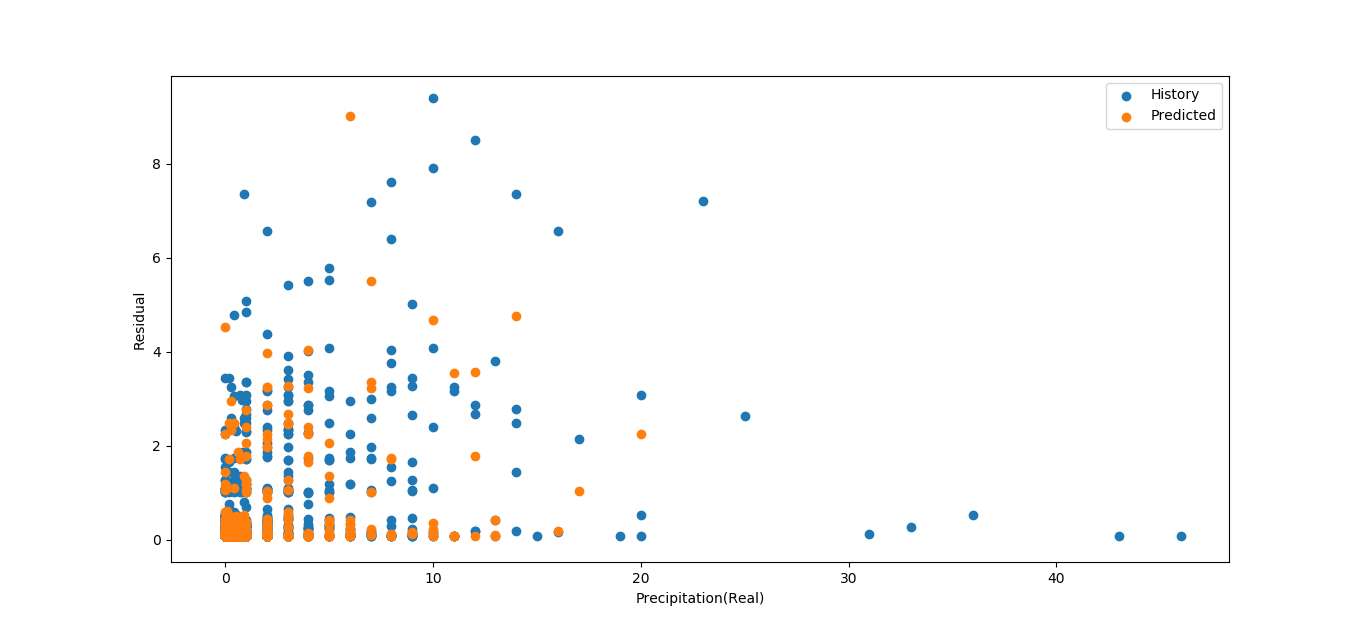
因此我按照原来的方法,把三个站点全部为0的无效数据剔除,最终只剩下了约2000组数据。线性和全连接层拟合出的结果都完全不能用。例如negative r squared以及像下图一样令人迷惑的残差图。
3. Classification attempt
区域回归失败的情况下,只能重新采用以往的旧思路。但平均的缺测宣告了LSTM的不可用。先试一下二分类是否能用,如果二分类效果还可以就往下进行多分类。
对其余的特征进行了重新的筛选。以下特征的缺测超过了剩余数据的20%,甚至70%,不能用。
缺测的特征:低云状、低云量、低云高、中云状、高云状、24小时变温、24小时变压
此外,标志1、标志2两个特征的值是固定的,也不能用。
对于分类任务来说,现在天气可能会指示当前的天气状态,也不能用。
所以剩下的特征只有:总云量、风向、风速、三小时变压、过去天气1、过去天气2、露点、能见度、温度。
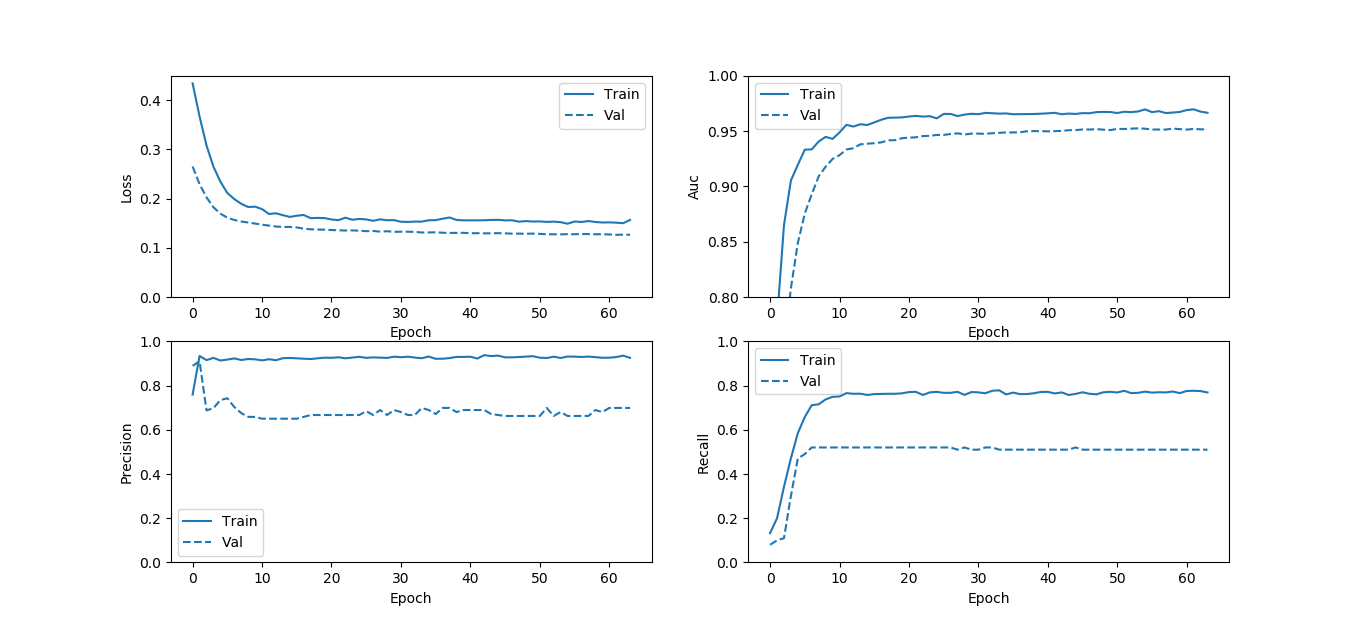
目前采用了两三种方法进行分类任务,一种最基本的一种加权的,还有一种是把数据进行平衡处理。基本的如下图:
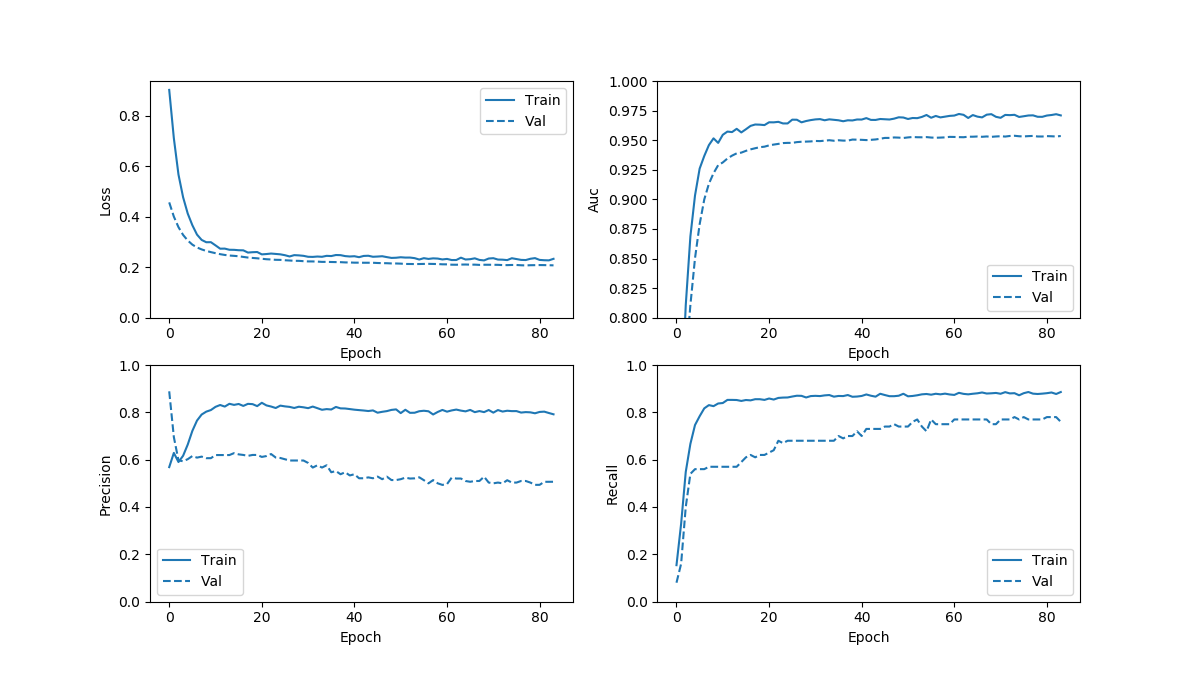
加权的如下图:
平衡处理有两个,分别是直接训练和另一个re-train,分别如下图:
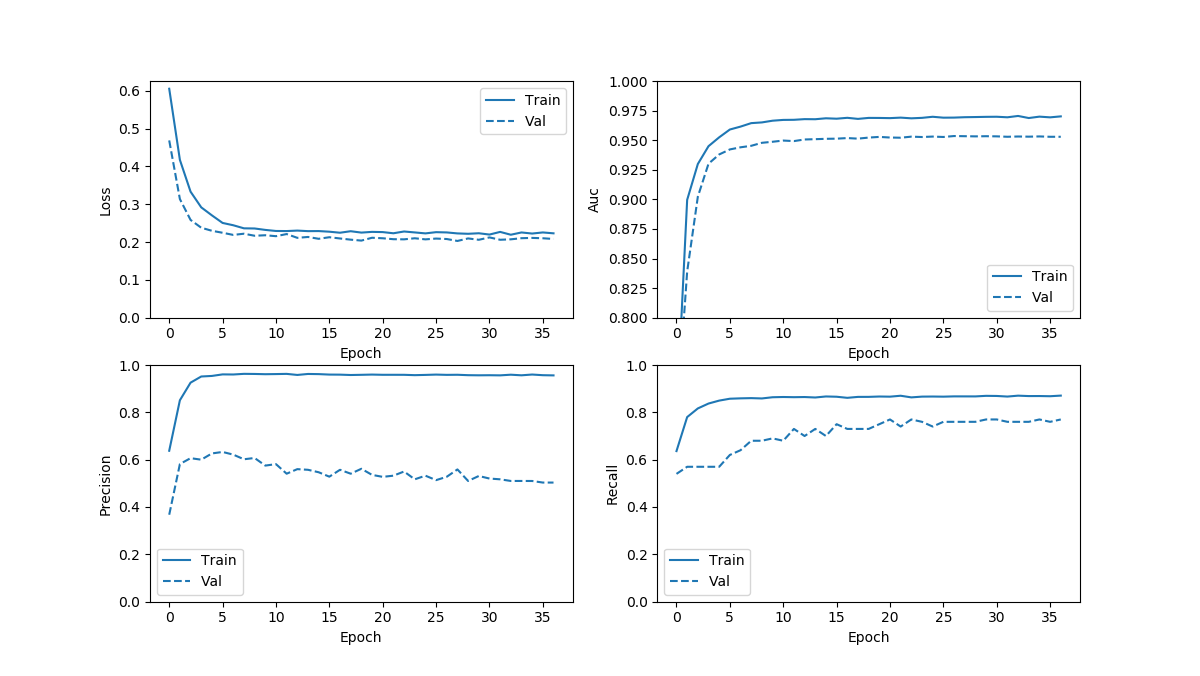
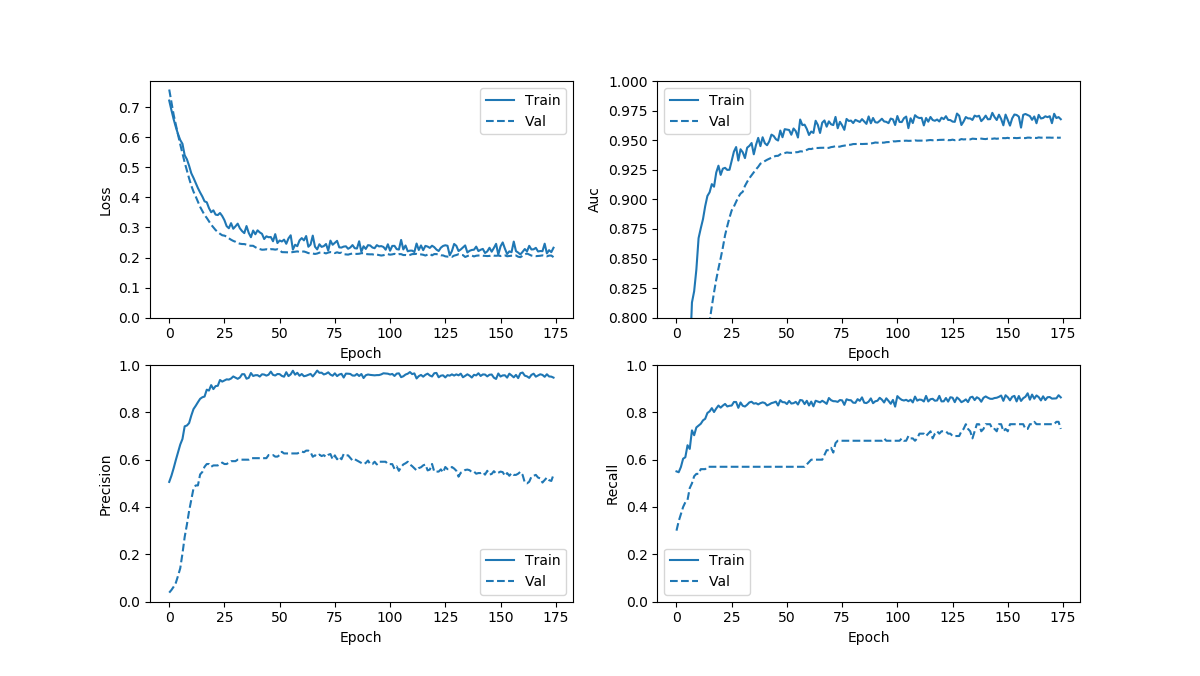
带有re-train的oversampling的几条曲线都不平滑,应该是steps_per_epoch取得太小导致,后面再看一下效果。
从loss来看作为模型来说应该没什么问题。模型的performance对比几组指标:
以及ROC_curve:
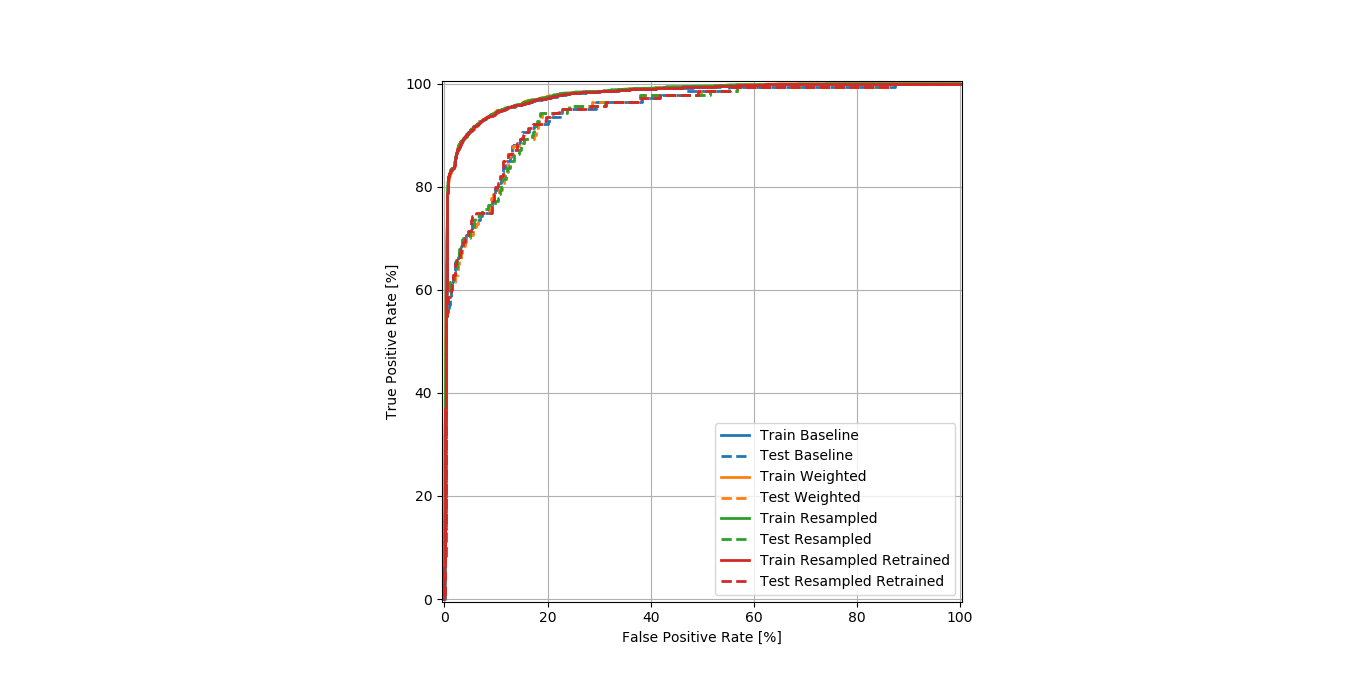

从AUC以及ROC曲线的表现来看,模型的预测能力比较好,加权略优于不加权。但加权模型的TPR远远高于不加权模型。考虑到我们的模型的主要工作是要把所有的降雨日挑出来,在TPR得到大幅提升的前提下,FPR做一点牺牲是可以的。
加权的基本思想还是基于不均衡数据分类。以降雨为例,通过让降雨日获得更大的权重,非降雨日获得较小的权重,传递给神经网络,从而让神经网络在训练的过程中更加重视“降雨”的特征。
oversample将原来非均衡的数据均衡化。选取非降雨与降雨分别构建数据集,以50-50赋予权重,就搭建起一个平衡的训练集。但由于
tf.data.Dataset.repeat()
的特性,默认repeat次数为无限次。这就导致训练集的大小是未知的,因此需要手动设置steps_per_epoch来进行训练。初始设置的steps_per_epoch以非降雨日的大小为基准重设了训练集大小来计算:
resampled_steps_per_epoch = np.ceil(2.0*neg/BATCH_SIZE)
但这样一来,一方面训练集是已平衡的数据,另一方面,由于训练集的大小增大了,每一轮训练的batch数就增大了,容易导致过拟合。为了防止这种情况的产生,因此才需要进行re-train。
re-train只改变了两个参数,分别是steps_per_epoch的大小,为防止过拟合,以及EPOCH的大小,为防止没有训练好就终止训练。仍然采用early_stopping来控制训练轮数,理论上能比较好的完成训练任务。
我上面re-train的结果很明显steps_per_epoch取小了,但我估计从几个模型的拟合度来看,不会有太好的变化。TPR的上限应该能达到0.8附近,应该不会再好了。
下周计划
1.文章投了
2.准备中期答辩
3.继续看oversampling方法,看一下效果
迁移到其他几个站点上看看效果
如果顺利的话尝试进行多分类
本文章使用limfx的vsocde插件快速发布