水平位移控制强化学习实现
pid调参
- 设置X_set为一个正常的信号,如下
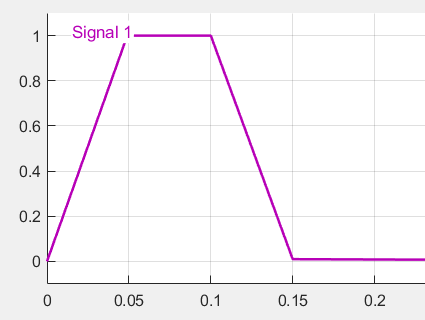
- 使用自带的调参优化方法,按照网上的教程调参,得到的最好的结果如下。
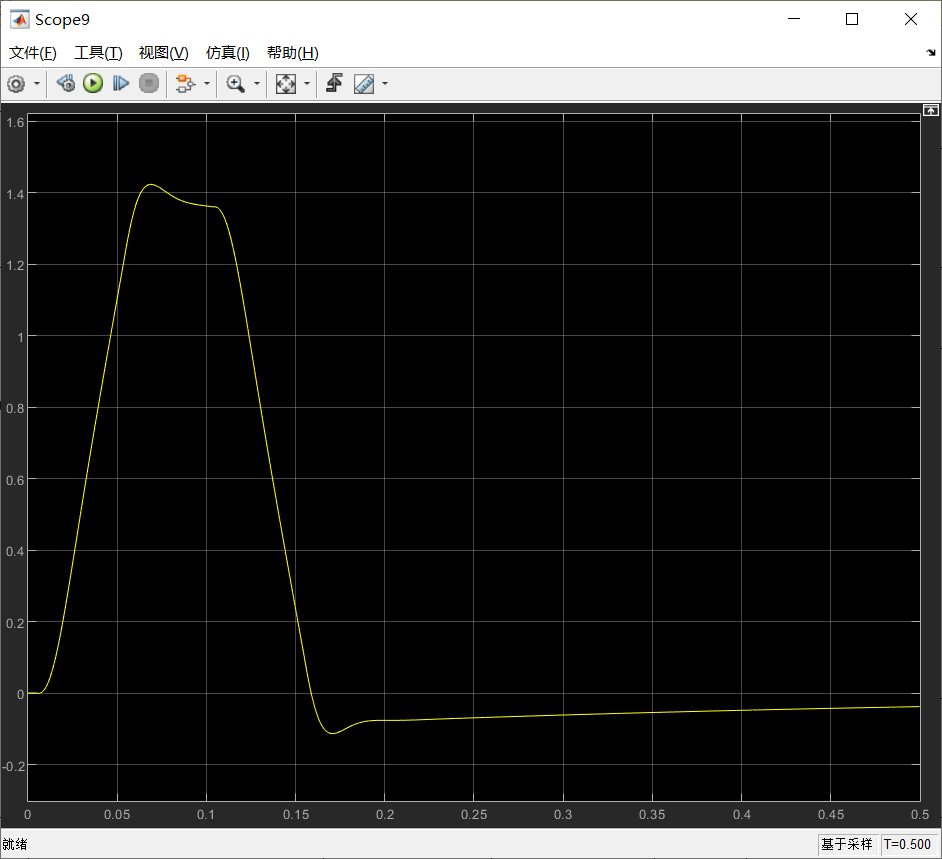
- 在PCSVP中搭建一样的模型,控制结果如下图所示:
 这个结果是在ode4,仿真时间0.5,步长1e-06时的结果,但是仿真时间过长。
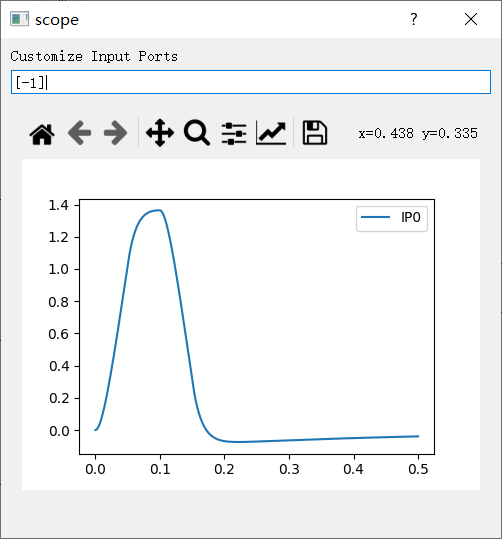
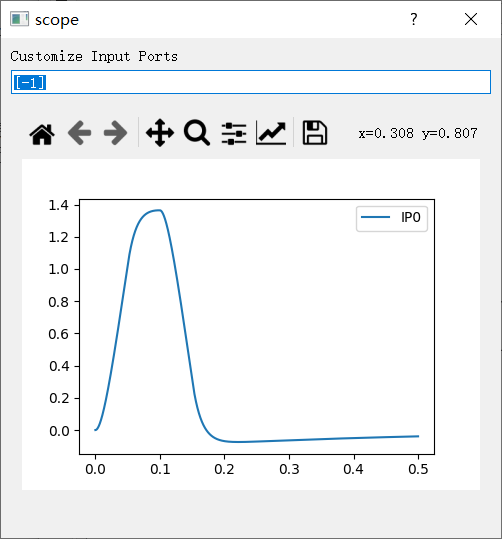
将其修改为ode3,仿真时间0.5,步长1e-05,结果如下图所示。
这个结果是在ode4,仿真时间0.5,步长1e-06时的结果,但是仿真时间过长。
将其修改为ode3,仿真时间0.5,步长1e-05,结果如下图所示。
rl
- 之前倒立摆小车进行强化学习训练时速度很慢,对强化学习算法进行改进,使用engine来保存action和environment信号进行传输,不再使用zmq进行通信
- 实现了仿真引擎EngineRL和两个新的信号传输系统,用于读写engine的成员变量。目前之前单action、多environment的情况。单action是考虑了gym.Env的step好像是需要action变量直接输入的。
- 实现了小周期不更新的设置,使目前的rl通信模块可以只在大步长进行输出,省去了很多麻烦。
- 实现了一个简单的demo在验证可以正常通信
from engineRL import EngineRL import numpy as np def create_simulator(): engine = EngineRL(lib_paths=["E:\\DSSim\\dssim_gui\\custom_files\\custom_library"]) with open("demo2.json") as fp: json_data = fp.read() engine.build(json_data) engine.set_parameter('start_time', 0) engine.set_parameter('stop_time', 0.5) engine.set_parameter('step_size', 0.1) return engine if __name__ == '__main__': simulator = create_simulator() for episode in range(5): simulator.reset() print(f"这是第{episode}轮训练:") action = np.array([1]) while True: print("action: ",action) observation,terminated =simulator.next_step(action) if terminated: simulator.terminate() break action = observation
速度提升
- 目前的性能测试如下:
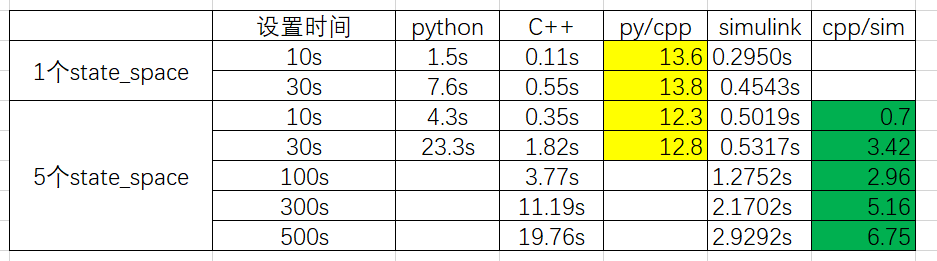
- 之前说着重看一下有没有在仿真过程中出现的大规模的数据复制的情况。
- 在实现的solver.cpp和三个系统的运算模块中,处理的数据都是在init方法中初始化过的vector对象,每次的修改都是针对对象本身做的修改,没有出现复制的情况。
- 而且实现比较简单,基本都是调用的vector.push_back方法,查到C++11中的emplace_back可能会有提升,减少一些对象创建复制的过程。将原来的实现进行了替换,性能没有提升。
- 目前来看每一个步骤都是很快的,是过多的循环导致速度变慢的。从simulink的结果也能推测出这点。
本文章使用limfx的vscode插件快速发布