水平位移控制器强化学习模型创建
- 按照原pid控制模型进行修改,替换原pid控制器
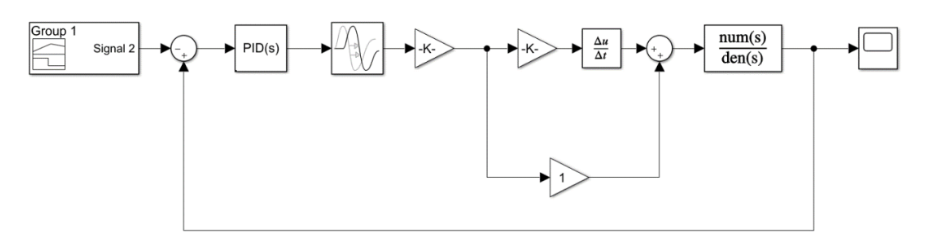

- 将预设的水平位移x_set作为一个观测值,模型输出的实际位移x_real作为另一个观测值。强化学习代理agent发出控制动作的信号对系统进行调节。x_set的输入波形如下。
- 创建了相应的环境
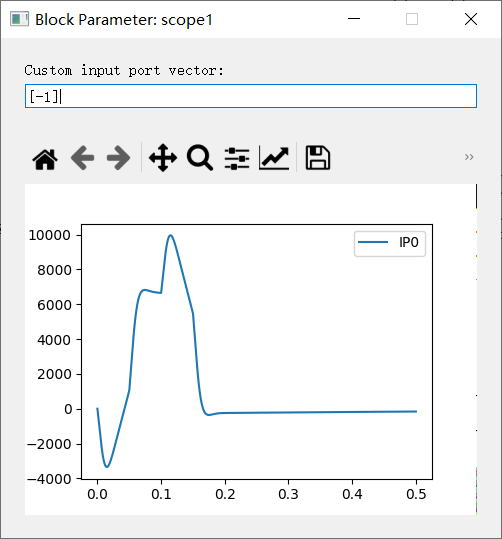
- 参考pid控制时,pid的控制输出如下图所示,范围在(-4000,10000),设置动作空间为(-10000,30000)
- 关注模型输出和预设的差值x_difference=|x_real-x_set|,为x_difference设置误差上限x_limit,超过3就会提前结束。期望x_difference在0附近,所以按照|x_limit-x_difference|来生成奖励。
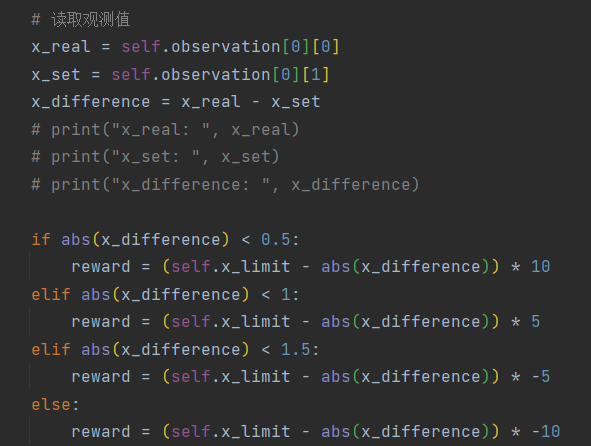 当提前结束时会给一个比较大的惩罚
当提前结束时会给一个比较大的惩罚

- 参考pid控制时,pid的控制输出如下图所示,范围在(-4000,10000),设置动作空间为(-10000,30000)
遇到的问题
- 在训练时每次都会提前结束,并且感觉没有学到什么东西,奖励和刚开始训练时没有提高
- 之前设置的提前结束的惩罚没有乘0.1,结果也很差,
本文章使用limfx的vscode插件快速发布