rl模型调参过程
奖励函数
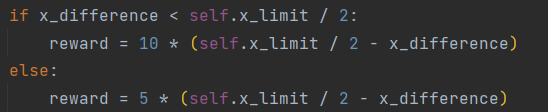
- 针对之前提到的奖励分段但是不连续的问题,重新设置奖励函数。
- 之前设置了x_limit,x_difference = |x_real-x_set|的值不能超过x_limit,期待x_difference的值为0左右
- 设置分段奖励,以x_limit/2为界限,小于该值是奖励为正,大于该值时奖励为负
 训练结果仍不太好,5000轮训练时仍然只能到500步左右
训练结果仍不太好,5000轮训练时仍然只能到500步左右
- 观测值太少,只有一个x_set和x_real,算法调了很久也没有什么效果。对奖励函数再进行设计
- 将斜率也设置为奖励的一个参考值,斜率逼近时奖励也应该扩大
- 奖励函数设置增加斜率变化,不再使用一次函数(1-x^0.4)
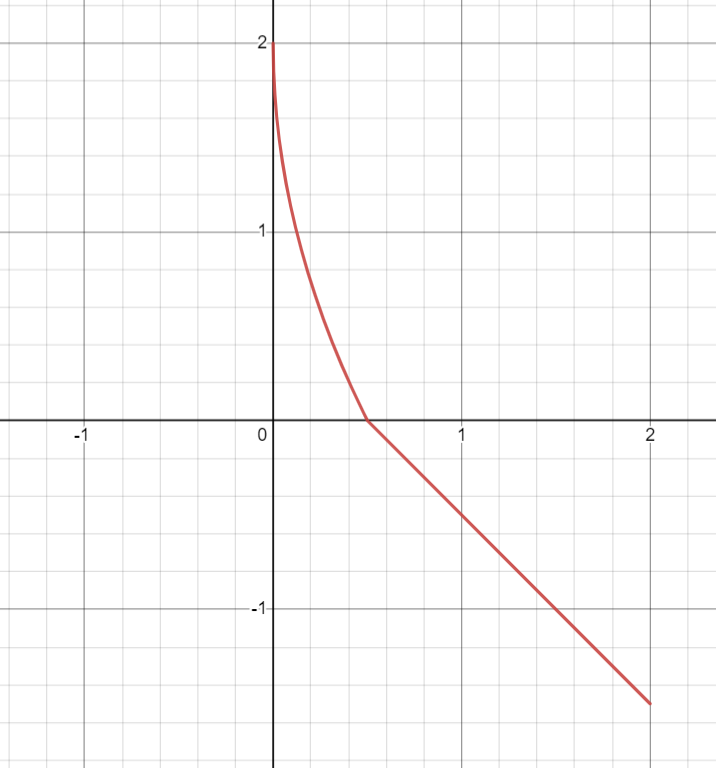
- 由于每一轮训练都会提前结束,所以为了鼓励agent以达到仿真终点为第一目标,对每一个step的奖励增大。在达到终点时给予一个大的奖励。对于x_difference的值,相应的奖励如下图
 对于x_real_deriv和x_set_deriv的也有相应的奖励,但是比重比较低
对于x_real_deriv和x_set_deriv的也有相应的奖励,但是比重比较低
RL算法
- SAC算法 只能坚持100步左右
- DDPG算法 效果和SAC算法差不多
- TD3 目前最多能到10141步,陷入局部最优解
目前解决方案
- 由于之前步长为1e-5时,总步数为50000步,最优的也只能到达10000,完成1/10。对于设定的X_SET来说只经历了最开始的爬坡阶段。
- 将步长改为1e-4不会对模型带来很大影响,使用pid的控制效果和之前相同。这样总步数可以减小到原来的1/10,难度会有大幅度的降低。
- 在去掉一个延时模块的情况下,可以达到比较好的控制效果
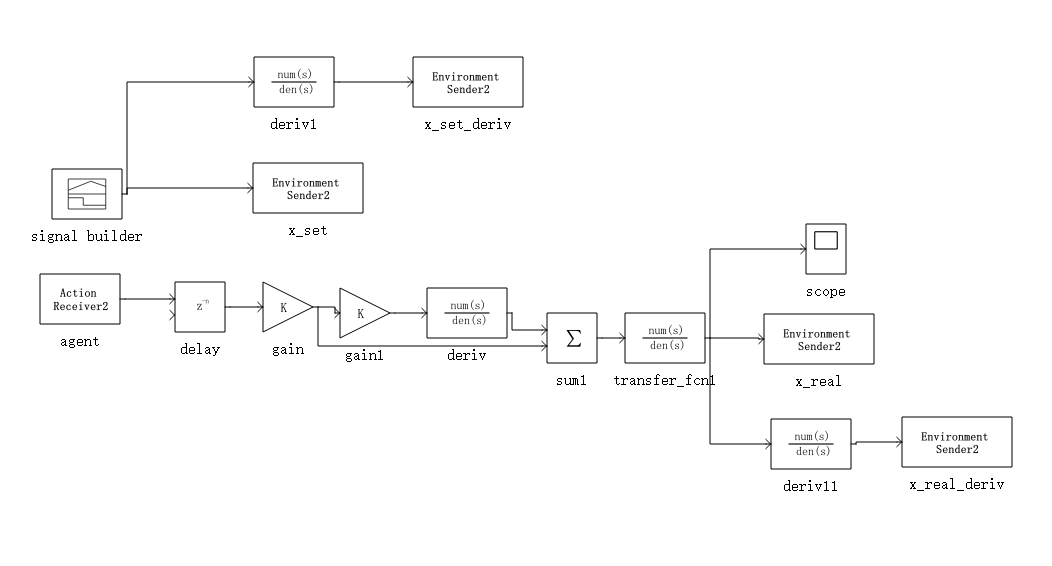
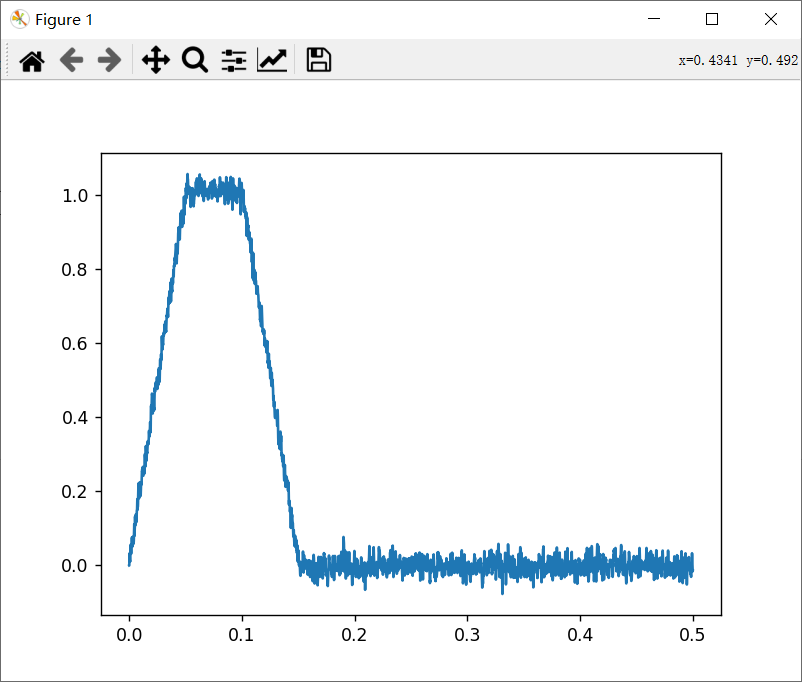
- 但是在加上延迟之后,由于刚开始不管做什么动作,经过delay模块都会输出0,所以在前几步的探索都没有反馈。前期的探索因为没有奖励回馈,所以是相对随机的,很容易在delay延时结束之后造成环境的崩溃。延时模块是下面内回路的近似。
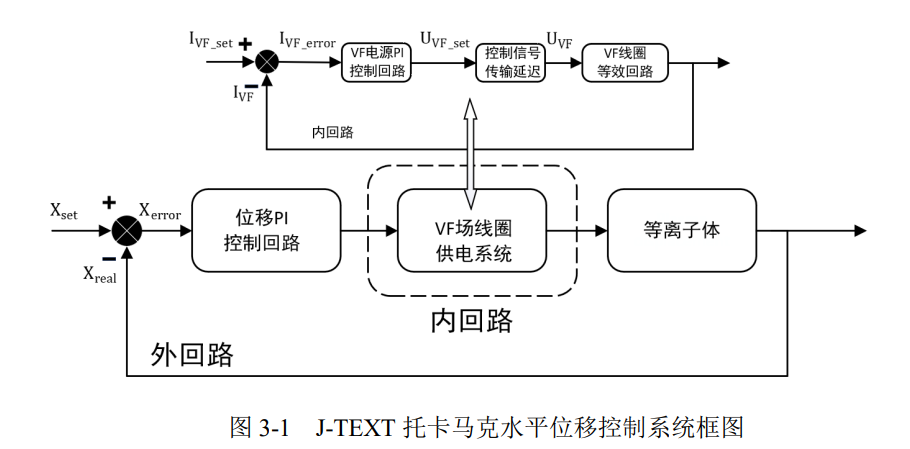

论文提纲
Dynamic system simulation(DSSim) upgrade for reinforcement learning
- Introduction
- 介绍dssim的现状(作为pcsvp的仿真框架,功能基本实现、现在的工作是发挥python优势结合人工智能算法,性能表现不足)
- 介绍强化学习在pcs领域的应用。提出对dssim进行改造(提高速度、RL接口开发)
- Optimization of the simulation process
- 介绍dssim原来的求解过程(方便理解后续的优化方法)
- 介绍优化的方法与优化结果 (主要介绍对求解过程的优化)
- Reinforcement learning function development
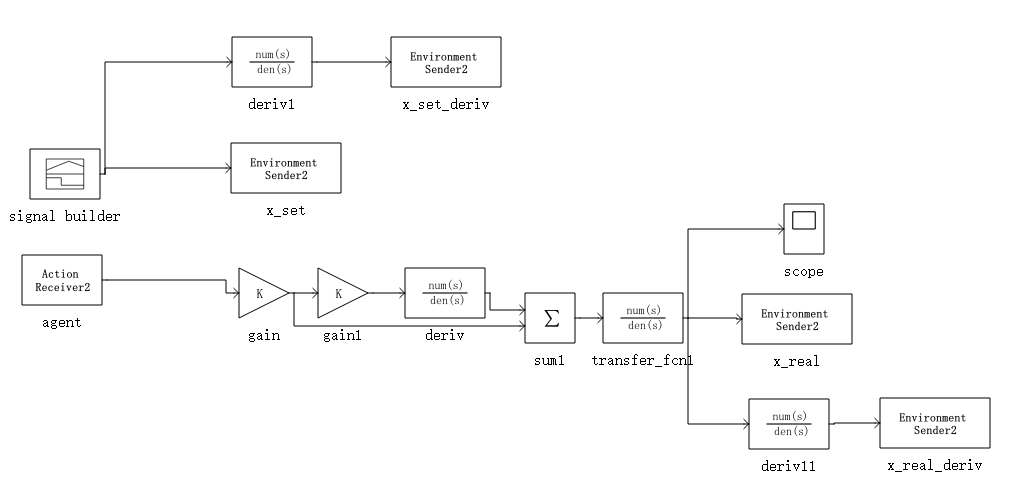
- 强化学习接口总体设计(按照强化学习训练的标准流程图分析)
- 定制引擎、定制系统功能介绍(定制引擎会在大步长过程中进行rl通信;定制系统是dssim中创建的便于用户使用的系统,可以与rl交互信息)
- Implementation
- 介绍水平位移控制系统(简单介绍jtext水平位移控制,提出pid控制的缺点主要是依赖经验)
- 使用强化学习控制,展示结果,说明可用性
- Conclusion
- 对dssim完成了面向强化学习的改造,主要工作是进行了性能提升与强化学习接口研发
- 后续任务是针对强化学习算法不易用的问题,进行算法封装,后期尝试使用system来包装算法模块,方便pcs研发人员的使用
本文章使用limfx的vscode插件快速发布