udpdk_api
这是udpdk dd 项目的api文档
api文档
api总览
int32_t dd_init(uint32_t mode, uint32_t ring_size, uint32_t job_id);
int32_t dd_status(uint32_t job_id);
int32_t dd_config(uint32_t channel_num, uint32_t blob_size, uint32_t stream_mode, uint32_t job_id);
int32_t dd_get_slice(ADC_SAMPLE *pSample, uint32_t num_group, uint32_t job_id);
int32_t dd_put_slice(ADC_SAMPLE *pSample, uint32_t num_group, uint32_t job_id);
int32_t dd_get_blob(ADC_SAMPLE *pSample, uint32_t job_id, uint32_t *blob_id); //risky
int32_t dd_get_blob_pop(ADC_SAMPLE *pSample, uint32_t job_id, uint32_t *blob_id);
int32_t dd_get_blob_sync(ADC_SAMPLE *pSample, uint32_t job_id, uint32_t *blob_id);
int32_t dd_get_blob_copy(ADC_SAMPLE *buf, uint32_t offset, uint32_t count);
uint32_t dd_count(uint32_t job_id);
uint32_t dd_close();
- 初始化函数
int32_t dd_init(uint32_t mode, uint32_t ring_size, uint32_t job_id);
参数:
mode目前有生产者,消费者两种模式,生产者指往buffer ring里面写数据,消费者指从buffer ring读数据
enum {
MODE_PRODUCER = 0,
MODE_CONSUMER
};
ring_size默认填0即可,会使用默认值DEFAULT_RING_SIZE,即128KB
#define DEFAULT_RING_SIZE (128*1024)
job_id则注意一致性,同一个采集任务的采集发送的job_id,生产者进程的job_id和消费者进程的job_id这三个要对应一致
- 查询buffer ring状态
int32_t dd_status(uint32_t job_id);
根据提供的job_id查询对应的buffer_ring的状态:使用,head,tail,丢弃
- 配置buffer ring
int32_t dd_config(uint32_t channel_num, uint32_t blob_size, uint32_t stream_mode, uint32_t job_id);
主要是按照16字节header里面的信息配置怎么读写buffer ring,注意这里生产者和消费者都需要配置,而且需要注意同一个采集任务的参数一致性
- dd_put_slice
int32_t dd_put_slice(ADC_SAMPLE *pSample, uint32_t num_group, uint32_t job_id);
这个api是给生产者用的,消费者无需关注,就是往buffer ring里面写采集数据
pSample为要put的数据
num_group,我更愿意叫做slice sample num,就是一个slice有几个点
job_id见上
- dd_get_slice
int32_t dd_get_slice(ADC_SAMPLE *pSample, uint32_t num_group, uint32_t job_id)
就是dd_put_slice的消费者版本,往buffer ring里面读采集数据,一次读一个slice的数据,参数和dd_put_slice是一致的
- dd_get_blob
int32_t dd_get_blob(ADC_SAMPLE *pSample, uint32_t job_id)
我们想要给用户提供的获取数据的api
用户提供一个pSample的缓冲区(注意要够这个blob数据的大小),然后把最新的一个blob的数据填进去,这个函数的返回值是0
int32_t dd_get_blob(ADC_SAMPLE *pSample, uint32_t job_id)
{
// 1. 获取队列中最后一个有效索引(最新写入的)
uint32_t prod_tail = (br->br_prod_tail - 1) & mask;
uint32_t sample_tail = (uint32_t)br->br_ring[prod_tail]; // 最新的 sample 索引
// 2. 计算 blob 起始位置:从 sample_tail 往前推 blob_size 个
uint32_t sample_start = (sample_tail - g_ctx[job_id].blob_size - 1) & mask;
// 3. 连续拷贝 blob_size 个 sample
uint32_t count = g_ctx[job_id].blob_size;
while(count--) {
memcpy(pSample, &sample[sample_start * channel_num], ...);
sample_start = (sample_start + 1) & mask; // 环形递增
pSample += channel_num;
}
return 0;
}
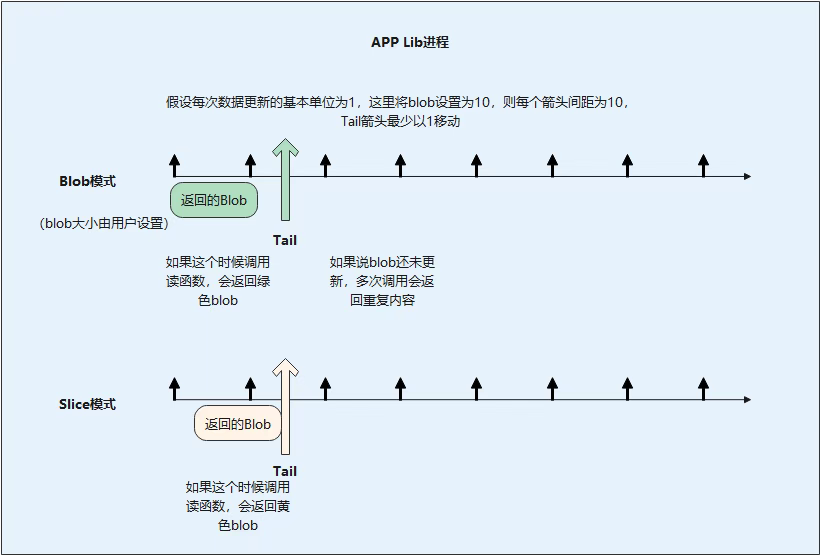
我们之前提到的Blob模式,Slice模式
其中Slice模式就是现在的dd_get_blob
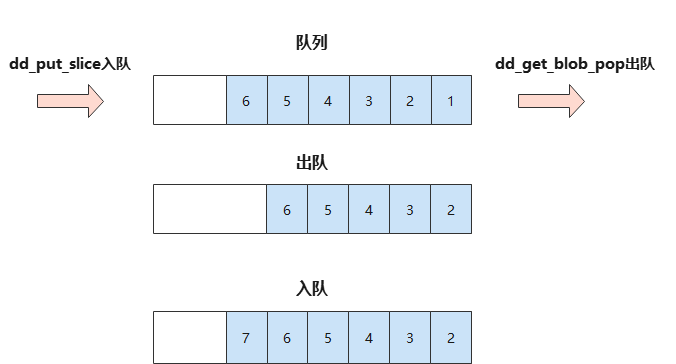
- dd_get_blob_pop
参数和dd_get_blob完全一致,就是返回的数据内容不同
int32_t dd_get_blob_pop(ADC_SAMPLE *pSample, uint32_t job_id, uint32_t *blob_id)
队列的思路,就是从队列里pop一个blob的数据
- dd_get_blob_sync
参数和dd_get_blob完全一致,就是返回的数据内容不同
int32_t dd_get_blob_pop(ADC_SAMPLE *pSample, uint32_t job_id, uint32_t *blob_id)
按 blob 对齐、非滑动、非覆盖的历史块读取,即只有当第 N 个完整的 blob(连续 blob_size 个 sample)写入后,才能读取它;否则只能读取上一个完整 blob(N-1)
对应图片中的Blob模式
本文章使用limfx的vscode插件快速发布