anomalyGPT文献阅读
论文贡献:首次将大型视觉-语言模型 (LVLMs)应用于 IAD,提出 AnomalyGPT,支持异常检测、定位、对话和少样本学习。
1 背景与问题
大型视觉-语言模型 (LVLMs) 的局限性:LVLMs 缺乏特定领域知识(如工业异常检测 IAD),且对物体局部细节的理解较弱。 现有 IAD 方法的局限性:传统 IAD 方法仅提供异常分数,需要手动设置阈值来区分正常和异常样本,这在实际生产环境中不实用。此外,这些方法通常遵循“一类一模型”范式,需要大量正常样本训练,不适合新型物体或动态环境。
2 数据输入与输出
2.1 训练数据集
数据集 | 类型 | 类别数 | 描述 |
|---|---|---|---|
MVTec-AD | 工业缺陷 | 15 | 5类纹理 + 10类物体,包含正常样本和多种异常类型 |
VisA | 工业缺陷 | 12 | 更复杂的工业产品图像 |
MVTec-LOCO-AD | 逻辑异常 | - | 包含结构和逻辑异常 |
CrackForest | 裂缝检测 | - | 道路裂缝图像 |
PandaGPT数据 | 多模态对话 | - | 用于保持LVLM的对话能力 |
2.2 异常模拟数据
采用 NSA 方法,基于 Cut-Paste 技术结合 Poisson 图像编辑生成模拟异常图像。Cut-Paste 从一张图像随机裁剪块贴到另一张,Poisson 编辑解决贴合不自然问题,使异常更真实。
2.3 问题和回答内容
查询格式:每个图像配文本描述 + “Is there any anomaly in the image?”。 描述示例: “This is a photo of leather, which should be brown and without any damage, flaw, defect, scratch, hole or broken part.”(提供物体预期属性)。
回答:先判断是否存在异常,若存在则指定数量和位置(使用 3×3 网格,如 “at the bottom left”)。
正常/异常文本:使用组合提示模板(如状态级 “flawless [o]” + 模板级 “a photo of the [c]”),[o] 为物体名,[c] 为状态。
3 模型结构
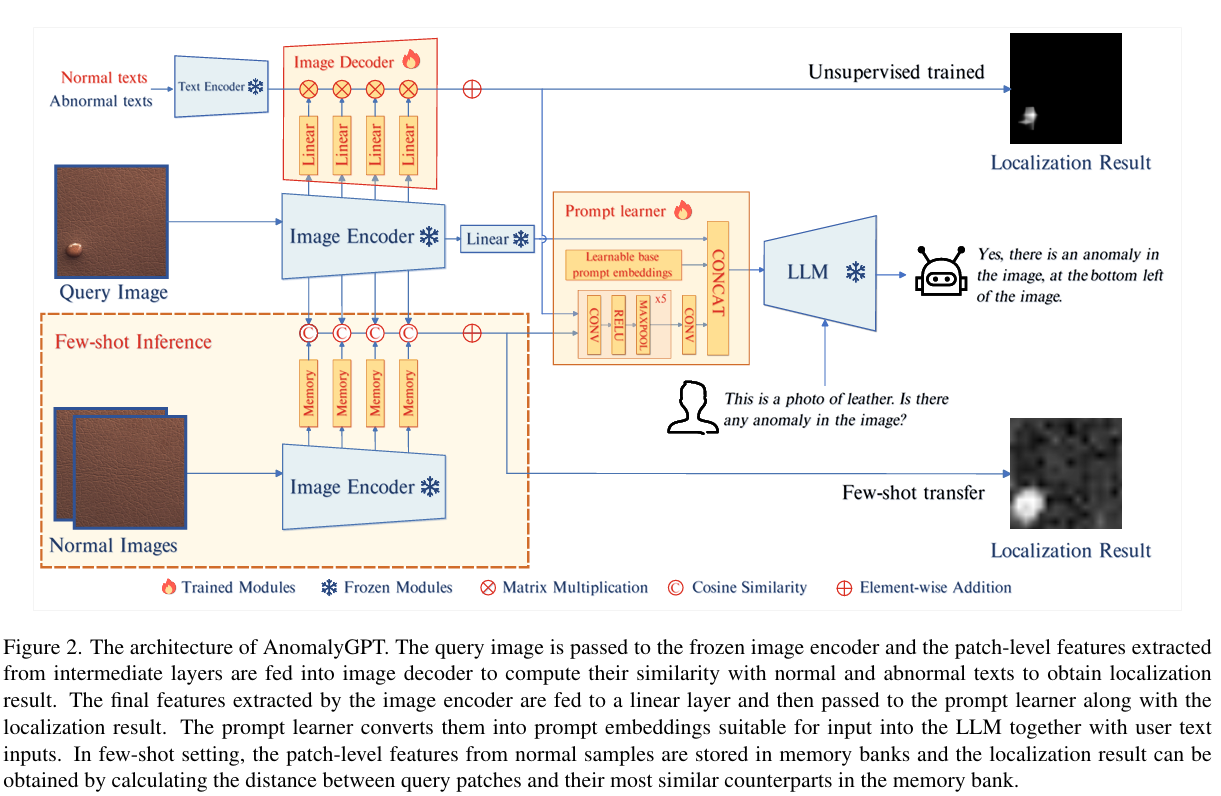
输入:查询图像(224×224)
Image Encoder(ImageBind-Huge): 不参与训练,输出全局特征与局部特征
Image Decoder:
无监督模式:计算输入与正常/异常文本特征的相似度(softmax + 上采样)。
少样本模式:使用正常样本,计算查询余弦相似度(1 - max cosine + 上采样)。
prompt leaner:
4.1 训练策略
采用两阶段训练:
阶段1: 预训练 (使用PandaGPT权重初始化)
├── 数据: PandaGPT多模态对话数据
├── 目标: 保持LLM的对话和理解能力
└── 冻结: ImageBind编码器
阶段2: 异常检测微调
├── 数据: MVTec-AD / VisA + 模拟异常 + SFT数据
├── 目标: 学习异常检测和定位
└── 训练组件: Prompt Learner, Image Decoder, LoRA参数
4.2 损失函数详解
4.2.1 总体损失结构
┌─────────────────────────────────────────────────────────────────────────┐
│ 总损失 (Total Loss) │
│ │
│ L_total = L_LM + L_pixel │
│ │
│ 其中: │
│ • L_LM: 语言模型损失 (Language Model Loss) │
│ • L_pixel: 像素级定位损失 (Pixel-level Localization Loss) │
│ │
│ L_pixel = Σ(L_focal + L_dice) for each layer │
└─────────────────────────────────────────────────────────────────────────┘
本文章使用limfx的vscode插件快速发布