2026年1月6日交流 姚老师交流问题
测延时
测试方法
取两个时间点Tstart和Tend,传输时延即为Td = Tend - Tstart
其中Tstart为采集卡FPGA端采集到第一个点时触发的上升沿
Tend为上位机收到的第一个包时触发的上升沿
然后用示波器同时显示两个上升沿,得到传输时延
测试结果
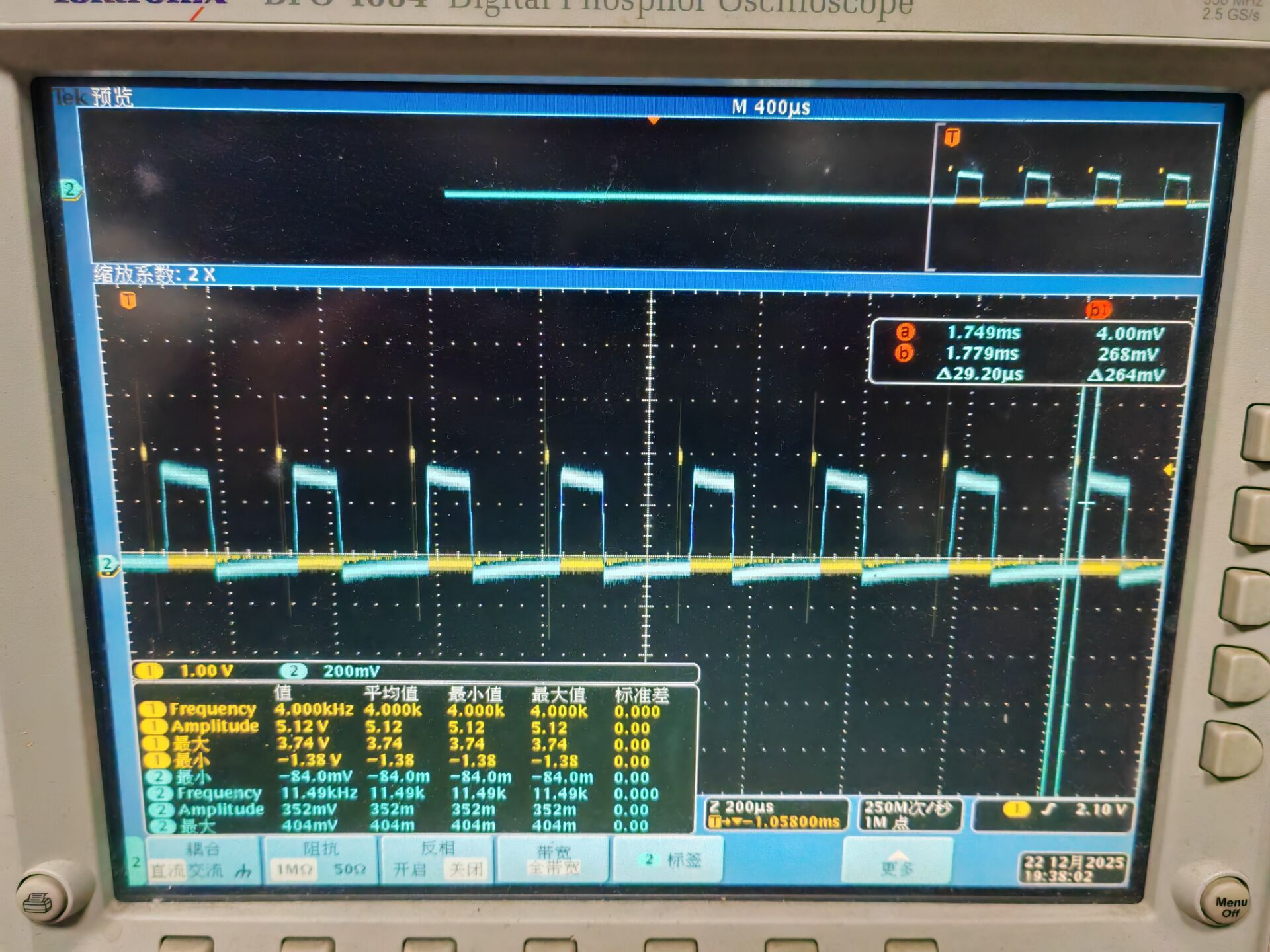
时延大概在30us
改进测量方案
用PTP(IEEE1588)来同步时钟测时延
测丢包(如何降低丢包率)
测试方法
在生产者程序dpdk_recv中加一个全局变量计数,然后ctrl+c退出时打印
static void signal_handler(int signum)
{
printf("Caught signal %d in pingpong main process\n", signum);
printf("packet count=%d, blob size=%d\n",packet_count,blob_size_u);
udpdk_interrupt(signum);
app_alive = 0;
}
while (app_alive) {
// Bounce incoming packets
int len = sizeof(cliaddr);
n = udpdk_recvfrom(sock, (void *)buf, sizeof(buf), 0, ( struct sockaddr *) &cliaddr, &len);
if (n > 0) {
DD_PayloadHeader *pHeader = (DD_PayloadHeader *)buf;
uint32_t blob_id = pHeader->data_blob_sample_cnt/pHeader->blob_size+1;
uint32_t slice_id = pHeader->data_blob_sample_cnt%pHeader->blob_size/pHeader->slice_size+1;
#if 1
if(dd_status(pHeader->job_id) < 0) { //first time
blob_size_u = pHeader->blob_size;
dd_init(MODE_PRODUCER, 0, pHeader->job_id);
dd_config(pHeader->channel_enable, pHeader->blob_size, 0, pHeader->job_id);
}
dd_put_slice((ADC_SAMPLE *)(buf + 16), pHeader->slice_size, pHeader->job_id);
packet_count++; //统计计数
#endif
}
}
然后消费者程序写一个dd_count.c,就是拿一个blob就增加一个packet_count,同样用来计算丢包
测试准备
上位机硬件:i7-8700K, 16GB RAM, E810
上位机设置:开启了1G大页内存*4,未开启超线程,grub配置
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on iommu=pt default_hugepagesz=1G hugepagesz=1G hugepages=4 isolcpus=1-5 nohz_full=1-5 rcu_nocbs=1-5”
config.ini配置
[dpdk]
lcores_primary=2
lcores_secondary=4
n_mem_channels=2
采集卡以2M采样率采集,开启192通道,每个通道数据是16bit,总数据载荷的产生速率为768MB/s,每个udp包的数据载荷是1936B,包速率为40万pps,然后我设置测试中的数据发送量为100万个sample,即20万个包。这个速率应该是远远没到硬件和dpdk的性能上限的。
我还用了dpdk的testpmd测试,20万个包零丢包。
(备注:我测试过更低采样率和包速率的情况,丢包率大概在千分之一)
测试1. 拿dpdk_recv去除多余的printf测丢包
packet count=192426, blob size=5
packet count=194030, blob size=5
packet count=194122, blob size=5
packet count=193543, blob size=5
packet count=192898, blob size=5
问题:丢包率极高,说明程序处理有问题,需要修改程序
这时我发现,假如说我把dpdk_recv程序中的 dd_put_slice 注释掉,那packet_count就能保证为20万
于是我怀疑是不是 dd_put_slice写入内存的速度太慢,导致前面dpdk/udpdk层的缓冲溢出了
然后我借助AI写了一个 dd_put_slice_bulk,能够去除循环,一次将包里所有sample一起写入buffer ring,然后测试
测试2. 拿dpdk_recv with dd_put_slice_bulk测丢包
packet count=195937, blob size=5
packet count=196374, blob size=5
packet count=194457, blob size=5
packet count=194407, blob size=5
packet count=195299, blob size=5
然后我问AI,AI建议我加大一点udpdk里面的缓冲区大小,我尝试将
udpdk_constant.h里面的一个常量加大到8192
/* Exchange memzone */
#define EXCH_MEMZONE_NAME "UDPDK_exchange_desc"
#define EXCH_SLOTS_NAME "UDPDK_exchange_slots"
#define EXCH_RING_SIZE 8192 // 2048 -> 8192
#define EXCH_RX_RING_NAME "UDPDK_exchange_ring_%u_RX"
#define EXCH_TX_RING_NAME "UDPDK_exchange_ring_%u_TX"
#define EXCH_BUF_SIZE BURST_SIZE
测试3. 加大缓冲区后测丢包
packet count=199617, blob size=5
packet count=198035, blob size=5
packet count=198424, blob size=5
packet count=199367, blob size=5
packet count=198122, blob size=5
关于这个常量我还尝试了4096,16384等等,结果是8192效果最好
最大的问题是我目前不知道丢包的问题根源在哪,只能尝试各种方法去优化然后测试
如何处理丢包
因为每个包包头可以计算出blob id,slice id,所以是可以给每个包正确的位置写入,然后如果有丢包后面看怎么把空位补上的。
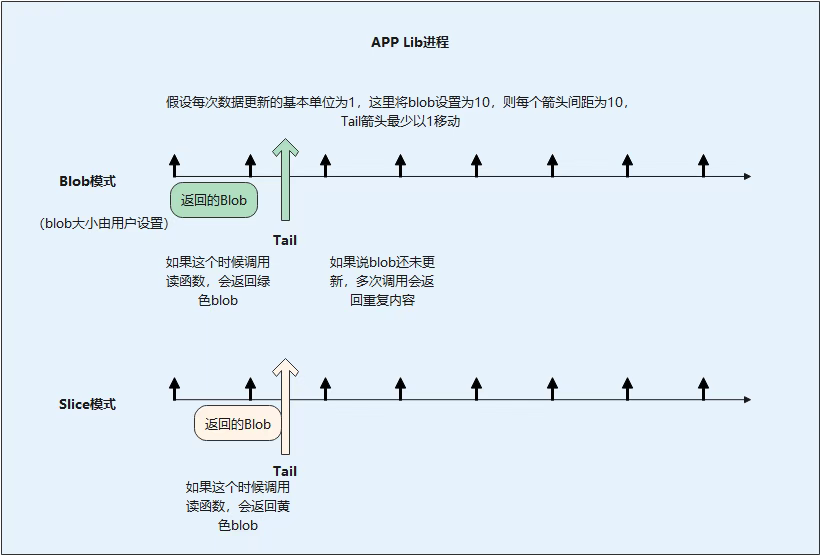
Blob模式下丢包处理
Blob模式下,可以考虑将上一个Blob,或者其他Blob中的对应位置UDP包数据内容,复制到现在的Blob丢包位置。
具体实现上,由于到来的数据填满一整个Blob后,Blob模式下才会读取新的Blob数据,因此如果Blob还没填满,当出现丢包问题时,用户读取的依然是上一个Blob里面的数据,此时丢包并不会影响本次Blob的丢包直接影响用户数据读取。
当本次Blob已经填入最后一个Slice时,用户将会开始读取本次Blob的数据。
- 如果在此之前,缺失晚到的UDP包已经接收到,则Blob填满,可以直接读取;
- 如果直到此时,缺失的UDP包依然没有收到,则判定该UDP包丢包,此时需要调用临近的Blob对应位置数据填写进来。
Slice模式下丢包处理
Slice模式下,设定丢包后的等待时间timeout,即丢包后可以继续等待多少个UDP包,或者等待接收到多少个采样点数据。
识别包头信息,发现UDP包编号存在跳变,某个编号的UDP包未接收到时,则在timeout内继续等待该编号的UDP包。
- 如果在timeout内,能够接受到该编号的UDP包,则将正确数据填进去;
- 若超过timeout后,依然没有接收到该编号的UDP包,则将丢包处的临近的UDP包数据复制到该位置。
反射内存模式下丢包处理
反射内存模式下,丢包的数据将不会覆盖旧数据,Blob里面对应的存储位置,仍然会有之前的Blob的数据保留,因此直接读取旧数据即可。
本文章使用limfx的vscode插件快速发布