主板端aurora对接ddaq基本完成
主板端aurora对接ddaq
主板端给5个子卡传输的数据分配一个512位的缓冲区,当检测到插有子卡的几个对应编号缓冲区均有数据,则开始将数据读出,并提供给后续b64模块。
测试使用的是模拟插入子卡的数据源,设定为100个采样点,每个udp包发送5个采样点的数据,使用2M采样率。
模拟的子卡数据源,通过200M时钟驱动,每次采样生成32个16位数据,之后转换到aurora设定的125M时钟域,拼接成32位,通过aurora回环功能传输到主卡部分。
通过ila抓取信号,测试结果如图:
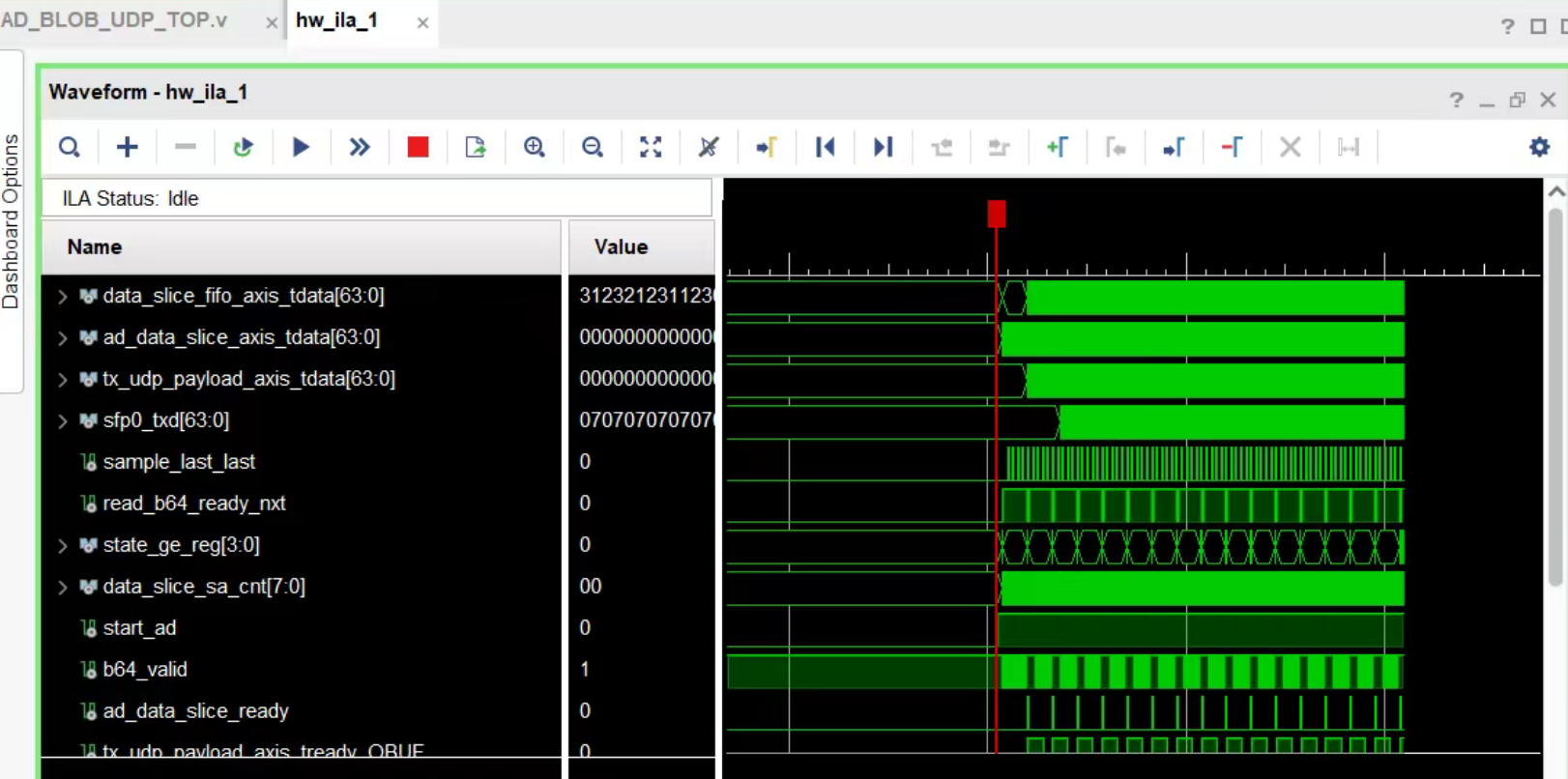
与之前正常运行的状态一致。
需完善的内容
- 主卡部分,原来ddaq程序有些地方还没有来得及修改,比如原来的ddaq里面,配置的的是6个子卡,但是现在只使用5个子卡,这一部分还没有修改;
- 目前测试的是回环测试,数据源需要换成使用实际子卡采集后通过aurora传输的真数据;
- 目前测试回环,用的一个子卡模块,同时模拟5个子卡,需要完善多子卡功能。
目前疑惑点
子卡程序在和姜子文研究时候,发现中能聚控那边,子卡采样率控制的设计很阴间。
子卡采样率通过控制SPI来实现,我们设想的就是,通过采样时钟信号控制SPI,SPI只需要自己进行数据传输,每次完成一个采样点采集数据的传输后,就等待下一次采样时钟信号到来;检测到采样时钟信号上升沿,就开始进行下一次采样,如果一直没有检测到,那就不进行采样了。
但是实际阅读中能聚控的程序,发现他们写的逻辑大概是:
- SPI在开始工作后传输一次数据,这个时间是固定的,用时a ns;
- 完成本次传输后,根据采样率计算采样间隔为b ns,那么就让SPI等待(b-a)ns。
换言之,中能聚控程序,子卡采样率的控制逻辑就是控制SPI传输后等待的时间。
感觉相对而言,采样时钟信号控制子卡采样率的思路会不会更好一些。
如果通过采样时钟信号控制子卡采样率,那么,需要给子卡传输的信号应该是只有这个采样时钟信号,采样时钟信号直接由主卡自己根据配置的采样率、本轮采样的采样点数目,以及本轮采样开始时间来产生,同时可以保证,5个子卡的采样工作,都是由同一个信号驱动,确保子卡采样工作同步。
中能聚控的程序,一方面是还需要添加主卡向子卡传输配置信息的功能,另一方面,各个子卡自己独立进行采样,采样时间长了之后会不会有不同步的问题。
此外,中能聚控程序本身也有问题,我们上板测试发现,子卡采样率到不了2M。因为子卡的SPI驱动时钟信号为160M,但是SPI传输一次采样的数据,至少需要82个时钟周期,也就是大概512.5ns,跟2M采样率的500ns采样间隔有区别。如果给200M的驱动时钟,采样率应该没问题,但是不确定会不会导致ad芯片驱动时序出错。
另外,之前1月在合肥那边,有个跟他们一起搞的SPI传输程序,这个SPI传输程序逻辑应该是跟我们设想的一致,而且也不存在采样率不够2M的情况,如果这个程序可以正常运行的话,其实可以考虑直接用。目前还需要个子卡采集端口的转接板,测试一下子卡ad采集功能,这个跟中能聚控那边的人说了。
本文章使用limfx的vscode插件快速发布