数据类型&&常量与变量
一、必备知识专题:进制转换、补码(后续介绍)
二、数据类型
基本类型
整型
有符号基本整型:(signed)int
有符号短整型: (signed) short (int)
有符号长整型: (signed) long (int)
有符号双长整型:(signed) long long (int)
无符号基本整型: unsigned int
无符号短整型: unsigned short (int)
无符号长整型: unsigned long (int)
有符号双长整型:unsigned long long (int)
字符型 char
布尔型 bool
实型(浮点型)
单精度:float
双精度:double
长双精度:float double
枚举类型 enum
空类型 (无值类型: void)
派生类型
数组类型
指针类型
结构类型 struct
联合类型 union
函数类型
三、常量与变量
3.1 常量与符号常量
常量概念
常量是在程序运行过程中,其值不能被改变的量
常量类型
字面常量(直接常量)
数值常量
整型常量
实型常量
字符串常量
字符常量
符号常量
只存在于预编译阶段(又称预处理,进行一些简单的代码文本替换工作),编译阶段就不存在了,经过预编译后,全部变为字面常量。常变量
C99中新增的内容,定义变量时前面加上const 关键字,
即: const int a=45;
常变量必须进行初始化,初始化后其值不可被改变
3.2 变量
变量概念
在程序运行过程中其值可以改变的量
变量名
1. 变量命名规则
C语言规定标识符只能由字母、数字和下划线_三种构成。且第一个字符必须是字母或者下划线_。
2. 标识符
标识符:在程序中使用的变量名、函数名、宏名等统称为标识符。
① 大写字母和小写字母被认为是两个不同的字符
② 标识符的长度无统一规定,随编译器而不同(VC++6.0是不超过32个字符,某版C中规定前八位有效,超过的话后边的自动丢弃)
③ 不能采用和关键字、C语言库函数名(后面介绍)相同的标识符
④ 尽量不要用下划线开头
⑤ 取名应遵循”见名知意“的原则
3. C语言里的关键字
表头 | 表头 | 表头 | 表头 | 表头 |
|---|---|---|---|---|
auto | break | case | char | const |
continue | default | do | double | else |
enum | extern | float | for | goto |
if | inline | int | long | register |
restrict | return | short | signed | sizeof |
static | struct | switch | typedef | union |
unsigned | void | volatile | while | _Bool |
_Complex | _Imaginary | restrict |
加粗的表示是C99中新增的关键字
4. 变量必须先定义后使用||先声明后使用
三、整型数据
3.1 整型常量
定义
整型常量即整常数,在C语言中可用3种形式表示:
十进制
十六进制 ,开头加0x
八进制 , 开头加0
详见补码等专题
3.2 整型变量
整型数据在内存中的存放形式
整型数据是以二进制补码形式存放于内存单元的。
详见补码等专题
整型变量分类
1. 有符号基本整型:(signed)int
2. 有符号短整型: (signed) short (int)
3. 有符号长整型: (signed) long (int)
4. 有符号双长整型:(signed) long long (int)
5. 无符号基本整型: unsigned int
6. 无符号短整型: unsigned short (int)
7. 无符号长整型: unsigned long (int)
8. 有符号双长整型:unsigned long long (int)
9. 字符型 char
10. 布尔型 bool
C标准中没有规定上述几种占多少个字节,所以具体占几个字节由编译器决定, 例如:
Turbo C:
① int || unsigned int 占2个字节
② short (int) || unsigned short (int) 当作int来处理
③ long (int)|| unsigned long (int) 占4个字节
VC++6.0:
① short (int) ||unsigned short (int) 占2字节
② int || unsigned int || long (int) || unsigned long (int) 占4个字节
C语言规定了:long型所占字节长度应该不小于int 型; short 型不长于int 型
格式声明符
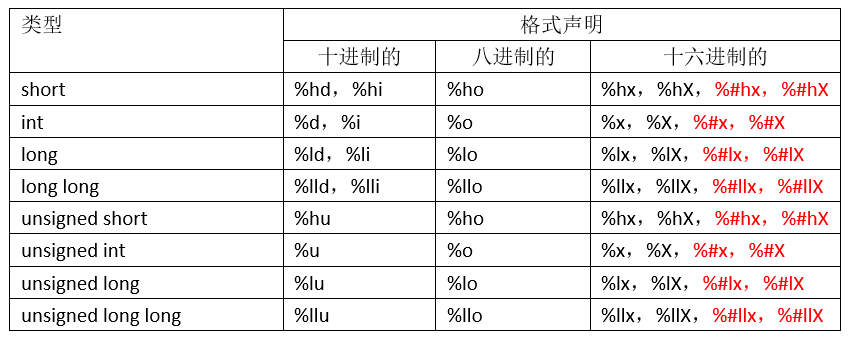
注意:黑色的格式声明 scanf可用,黑色和红色的格式声明 printf可用。
整型数据类型转换符

不同整型数据类型所能表示的数据范围

数据溢出问题
五、(实型)浮点型数据
5.1 实型常量
表示形式
1. 十进制小数形式
314.15
0.000867
2. 规范化指数表示形式
在字母E(e)之前的小数部分中,小数点左边有且只有一位非零整数
上述两个数字可以这样表示:
3.1415e+2
8.67e-4
浮点型常量数据类型转换符
写一个小数,末尾不加类型转换符 | 写一个小数,末尾加f或F | 写一个小数,末尾加l或L |
|---|---|---|
默认按双精度double型处理运算 | 告诉系统按单精度浮点型float处理 | 告诉系统按长双精度 long double型处理 |
那么问题来了
float a=3.14159;
//3.14159是一个常量,f是一个变量,float a,系统会为其分配4个字节;不在3.14159后边加一个f或者F,系统会按照double型常量处理,给其分配8个字节,
//这时8字节的常量赋给4字节的变量,有的编译系统就会弹出警告:这样可能会产生精度丢失的问题。
//这样一般不会影响运行,但是可能会影响结果的精确度。
//所以我们要注意加上转换符,强制指定常量类型。
存储方式&&取值范围
从上述两个例子我们可以看到规范化指数表达形式书写简单,几个数字和字母就表达了原来很长的一串数字。
计算机存储与其类似,也是又规范化指数表达形式进行存储的,只不过是以2为底数,不是以10为底数。
在内存中,一个浮点型数据被分成了3部分存储,符号、小数部分、指数部分。(看情况填空,人要说三部分就这样写,两部分就别说数符位)
数符位 | 小数部分 | 指数部分 |
|---|
可以看到同样占4个字节,浮点型数据要比整型数据类型所能表达的数字范围更广。然而浮点型并不能完全精确的表达所有取值范围内的数,当阶数太大或者太小时,浮点型数据所不能表达的数字越来越多。

看精度主要是看他能保存几位有效数字:
比如1.2222 2222 4589这个数字,虽然在浮点数的取值范围内,但是其保存的时,把2222 2222 4589这个数字保存到二进制小数位部分(23bit),先得转换成二进制,然而经转换发现23位根本存放不了这个十进制数,这23位二进制所能存放的最大十进制数是 8388 607,也就是这23位二进制只能存放十进制的小数点后边的6~7位。
5.2 实型变量
分类
1. 单精度:float
2. 双精度:double
3. 长双精度:long double
C语言也没有规定每种实型占多少字节
Turbo C 中 long double 占16个字节
VC++ 6.0 中 long double 占8个字节
float 占4个
double 占8个
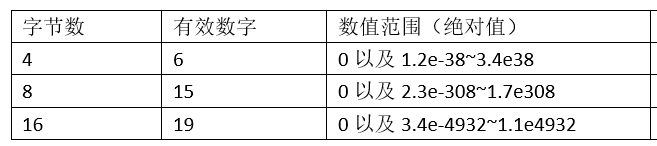
注:从数值的左边第一个不为 0的数字起,一直数到这个数字结東,中间的数字叫这个值的有效数字(如0.618的有效数字有三个,分别是6,1,8)
关于浮点数的存储范围见专题(浮点数的存储及取值范围)
输出格式说明符
float | double | double long |
|---|---|---|
%f | %f | %Lf 或 %lf |
指数形式输出,把其中的f都换成e即可
舍入误差
float i = 4.7f;
printf("%.10f\n",i);
if (i==4.7)
printf("**********\n");
else
{
printf("^^^^^^^^^^\n");
}
//结果:
4.6999998093
^^^^^^^^^^
可以看到浮点型数据不能与一个实数进行比较相等?
该如何解决呢?
比较浮点数是否相等的标准方法是首先确定在比较中允许的误差, 然后看一个数是否在另一个数的此误差范围内,可以采用如下方式:
if ( ( value1 >= ( value2 - error ) ) && ( value1 ⇐ ( value2 + error ) ) )
而更高级的方法如下:
if ( abs( value1 - value2 ) ⇐ error )
float i = 4.7f;
printf("%.10f\n",i);
if ( abs(i-4.7f)<=0.00001)
printf("**********\n");
else
printf("^^^^^^^^^^\n");
//输出结果:
4.6999998093
**********
六、字符型数据
6.1 字符代码
字符在内存中是以整数形式存储的,一个字符对应一个特定的整数,计算机能识别的字符是有限的,并不是任一个字符都可以被计算机识别。
ASCII码一共128个(代码为0~127), 所以最多用7位就可以表示一个字符。 所以C语言中规定用1个字节(8位)来存放一个字符。字符型变量一般占用1个字节
#include <stdio.h>
#include <stdlib.h>
#define PI 'A'
int main(void)
{
printf("%d\n",sizeof(PI));//结果:4
system("pause");
return 0;
}
从例子中可以看到,字符型字面常量占用的是4个字节。
ASCII表
我们已经知道了有128个字符,这些分别是:
第一组:数字09;字符码为[48,57]
第二组:字母AZ:字符码[65,90]
第四组:字母a~z: 字符码[97,122]
其他
规律:一个字母的小写比大写的字符的ASCII码大32
一个字母的小写比大写的字符的ASCII码大32
6.2 转义字符表
类型 | 转义字符 | 字符值 | 输出结果 | 可显性 | ||
|---|---|---|---|---|---|---|
一般转义字符 | \' | 一个单撇号(') | 可显 | |||
\'' | 一个双撇号('') | 输出此字符 | ||||
\? | 一个问号(?) | 输出此字符 | ||||
\\ | 一个反斜线(\) | 输出此字符 | ||||
\a | 警告 | 产生声音或视觉信号 | 不可显 | |||
\b | 退格 | 将当前位置后退一个字符 | ||||
\f | 换页 | 将当前位置移到下一页的开头 | ||||
\n | 换行 | 将当前位置移到下一行的开头 | ||||
\r | 回车 | 将当前位置移到本行的开头 | ||||
\t | 水平制表符 | 将当前位置移到下一个tab位置 | ||||
\v | 垂直制表符 | 将当前位置移到下一个垂直制表对齐点 | ||||
八进制转义字符 | \o o代表一个一位或两位或三位的十六进制数字 | 与该八进制码对应的ASCII字符 | 与该八进制对应的字符 | 可显 | ||
十六进制转义字符 | \xh h代表一个一位或两位的十六进制数字 | 与该十六进制码对应的ASCII字符 | 与该十六进制对应的字符 |
6.3 字符变量
char c ='?';
printf ("%d %c\n",c,c)
//输出结果 63 ?
印证了字符型数据在内存中的存储形式
也可以像整型数据那样对字符型变量进行算术运算,就是对字符的ASCII码进行操作。
字符型数据和整型数据之间可以相互赋值
char c;
int i;
c='A';
printf ("1.初始时c='A',c的值是 %d %c\n" ,c,c);
c = c +32;
printf ("2.经过c = c +32运算后c的值是 %d %c\n" ,c,c);
i=c;
printf ("3.经过i=c,将c的值赋给i后,二者现在的值是:\n");
printf ("%d is %c\n",i,c);
printf ("%c is %d\n",c,c);
/*输出结果为:
1.初始时c='A',c的值是 65 A
2.经过c = c +32运算后c的值是 97 a
3.经过i=c,将c的值赋给i后,二者现在的值是:
97 is a
a is 97
*/
字符型数据算是一种特殊的整型,也分signed 和 unsigned,取值范围不同,但是并没有什么卵用,因为字符代码是从0开始的,也就那几个。
??? 如果以字符格式输出一个大于256的数字结果是什么? 输出一个空字符的位置。
6.4 字符串(后面有专题介绍)
要与字符做区别
字符串不是C里的专门的一种基本数据类型。
本文章使用limfx的vsocde插件快速发布