知乎回答打分建模
背景
我们需要根据知乎的回答信息重新打分,让小甲醛筛选适合他读取的消息。
小甲醛适合读文字少,点赞多的回答,这是基本要求。
拥有的数据为:voteUpCount、commentCount、contentLength、offsetNum(这个是回答在知乎中的排序的序号)
失败的尝试
首先,我对获取的数据的这四个属性进行了主成分分析,结果非常 amazing 啊,第一主成分占比 95% 多,但是根据矩阵可以发现,这四个属性都是正系数,第二主成分前两个属性是负系数,第三个属性是正系数。
为什么说这问题很大,因为第一主成分的含义是:点赞多,答案字数多。第二主成分点赞和答案的系数才相反,这就和我们的原则冲突。
想了一下,因为主成分分析是无监督学习,他只是对数据进行纯粹的分析,将方差大的维度变成主成分,但是并没有考虑实际的意义。
换句话说,我们可以用第一个主成分和第二个主成分分别表示投票数和字数,那么我们为什么不直接用这两个属性呢?
再次 PCA
我们转换思路,将 contentLength 从中间剔除,用剩下三个属性进行主成分分析。
显然,之后我们只保留一个主成分,这样就将我们已知的三个表征相似属性的属性降维成一个属性,如果第一主成分的贡献率很高,而且三个属性系数接近,证明三个属性都有意义。
结果发现,第一主成分贡献率 99.54%,转化矩阵如下:
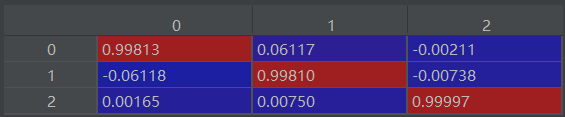
说明这三个属性分别就是三个主成分,也就是说,我们只用考虑 voteUpCount。
其实这也是有用的,因为我们知道了 voteUpCount 起到了决定因素,而不是 commentCount
考虑 contentLength
OK,又回到最初的起点,呆呆地坐在电脑前,现在证明了只用管 voteUpCount、contentLength 这两个属性,然后我们设计一个打分函数,把两个变量变成一个分数就万事大吉了。
如上,我们把集中的部分单独拿出来,如下图:
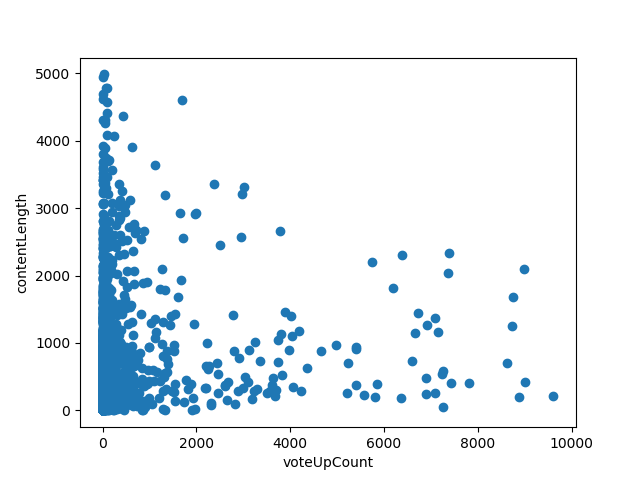
现在看的很清楚了,大部分 voteUpCount 在小于1000,这部分是不太好的答案,而在不太好的答案中,还有字数多的离谱的答案,这部分肯定是要筛掉的。而在点赞 2000~10000之间的散点,我们就很希望可以得到。
设计函数
没必要花里胡哨了,我们直接用手设计一下,先让两者满分都是 100 分
点赞数超过 1w 为满分,低于 1k 为 0 分,之间为线性函数。
字数分数按分数段进行,如下分数段:
字数范围 | 分数 |
|---|---|
0~100 | 100 |
100~200 | 75 |
200~500 | 50 |
>500 | 0 |
这样的话,我们可以凭借点赞数基本判断答案的优劣,让点赞的加权高于字数,由于字数的分数区分度大,所以可以起到作用。
最基本原则,水答案(点赞 0 分,字数 100 分)会低于字数多,但是点赞也多的答案(点赞50分,字数100分),所以可得加权系数为:点赞 0.7,字数 0.3
效果分析

如图,效果还是不错的,我们稍微分析一下:
点赞少的,肯定分数低,因为点赞数图中后半段上半部分是空的,说明点赞少一定是低分。
两个在 70 的谜之突起,说明在 70 分左右,集中了点赞多、文章长的,这很符合我们的设定,我们之后在小甲醛读内容时,如果人说一句 “下一条” 让小甲醛跳过这个问题,这样就可以根据人的心情决定听不听点赞多、字数多的评论了。
根据实际情况,有些热搜问题才刚刚出现,所以点赞人数不是很多,这个时候就会出现很多 30 分的 score,因为 content 是 100 分,我们可以排序的时候用 【score,voteUpCount,contentLength】排序,结果就会比较好。再加上我们只会从知乎的默认排序中从前往后获取答案,所以得到的答案本身质量就比较高。
本文章使用limfx的vsocde插件快速发布