9.2 链表
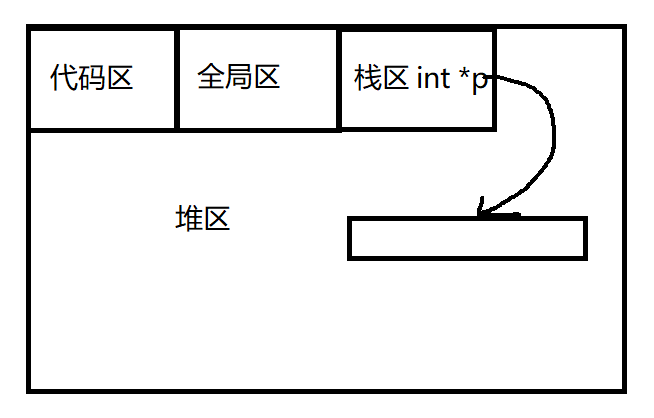
一、背景知识——内存
内存4区
代码区:函数代码存放在代码区函数名就是这个函数的地址。
全局区:全局的变量字符串常量初识化 int a;
栈区:告诉计算机 int double char,定义一个变量c,由系统开辟和释放
栈区的内存就像公交车的座位,你坐着的时候没人抢,你一走立马有人坐。堆区:自己确定有多大。装什么数据?用完之后还要不要继续用?自己需要决定开辟释放。
堆区的内存就像是你租的房子,只要你不说不租,你无论出去旅游还是干啥,房子都在那里,没人破门而入。
int *p;
p=(int *)malloc(sizeof(int));
二、链表的相关概念
什么是链表
动态的进行存储分配的一种数据结构,区别于数组,链表可以不连续存储,而数组无论数据存多长,都需要一块连续的内存空间,造成内存的浪费。链表可以见缝插针。
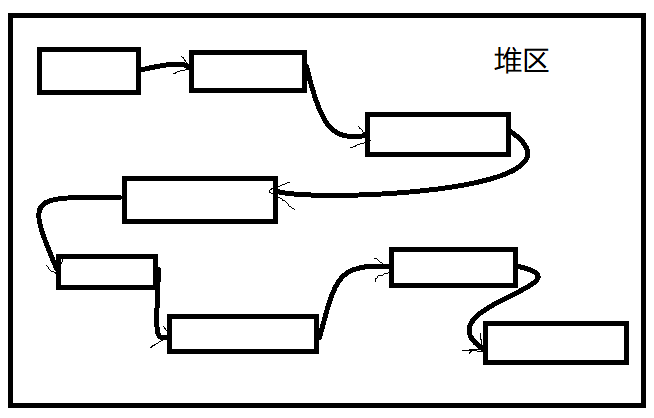
链表的相关概念
结点 存储本身的数据+存储后继数据空间的地址,二部分构成了一个整体,称之为结点.(自己的理解)
数据域 结点中存放有效数据的空间
指针域 结点中存放后继数据空间位置的存储空间
首结点 存放第一个有效数据的节点
尾结点 存放最后一个有效数据的节点,其指针域为空NULL。
头结点 头结点的数据类型和首结点一样
头结点是首结点前面的那个结点
其数据域一般不存放有效数据,指针域存放了首结点的地址
设置头结点的目的是为了方便对链表进行操作头指针 指向头结点,存放了头结点的地址
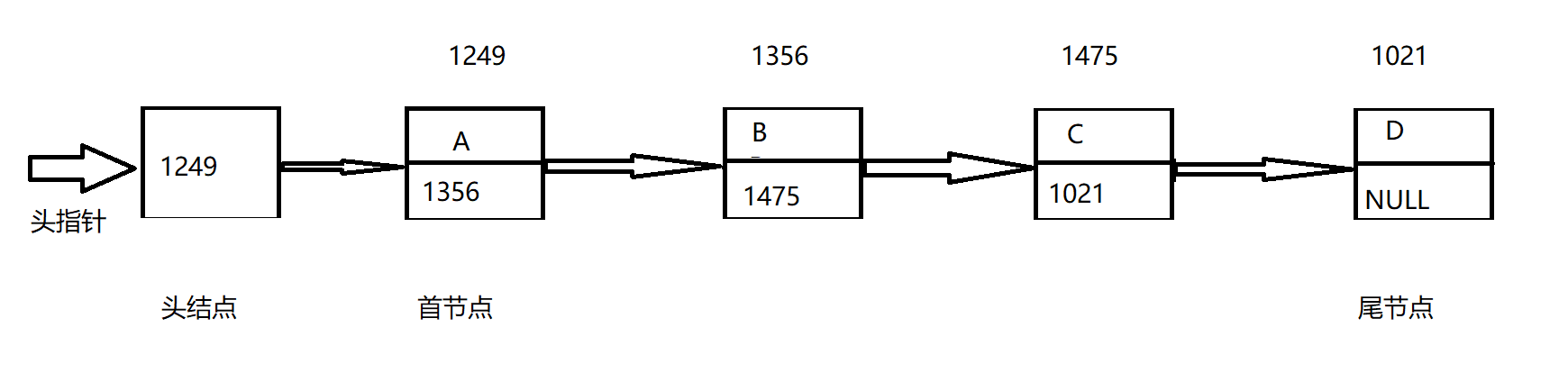
确定一个链表需要几个元素
分析确定一个数组需要几个元素?
首地址
元素个数
有效元素个数
如果希望通过一个函数来对链表进行处理,我们至少需要接收链表的哪些参数?
确定一个链表只需要知道链表的头指针即可
通过头指针可以找到头结点,首结点,进而确定整个链表。
三、链表的分类
单链表
双链表:每一个结点有两个指针域
循环链表:能通过任何一个结点找到其他所有的结点
非循环链表:
四、链表的操作【其他操作见下一节】
创建并输出非循环单向动态链表
从前面的介绍来看,链表是一种数据存储结构,又很多结点,每个结点包含两部分,一部分存放数据,另一部分存放下一个结点的地址。 从这个描述来看,比对之前学的语法,可以发现结构体可以实现链表的结构。
/*
1. 创建一个单向动态链表
2. 判断链表是否为空
3. 输出链表数据
*/
# include <stdio.h>
# include <malloc.h>
# include <stdlib.h>
typedef struct node
{
int data;
struct node * Pnext;
}NODE,*PNODE; //NODE等价于 struct node *PNODE等价于struct * node
//函数声明
NODE * creat_list(void); //创建一个非循环单链表
void traverse_list(NODE *); //将这个链表的所有结点输出
int main (void)
{
NODE * pHead = NULL;
pHead = creat_list();
traverse_list(pHead);
system("pause");
return 0;
}
//创建一个链表
PNODE creat_list(void)
{
int len;//用来临时存放用户输入的结点的个数
int val;//用来临时存放用户输入的结点的数据
int i;
PNODE pHead;
PNODE pTail;
PNODE pNew;
//记得把声明写在前面,否则编译不过去
printf("请输入您要输入的链表的结点个数:\nlen=");
scanf("%d",&len);
pHead = (PNODE)malloc(sizeof(NODE));
//生成了一个头结点
pTail = pHead; //再没生成链表前,尾结点就连着头结点这一个
pTail->Pnext = NULL; //这句是必须的,因为可能用户输入的是0.就没有造任何新结点
if(NULL== pHead)
{
printf("内存分配失败,程序终止\n");
exit(-1);//内存都分配失败了,这个程序就没有继续的必要了
}
for(i=0;i<len;++i)
{
printf("请输入第%d个结点的数据",i+1);
scanf("%d",&val);
pNew = (PNODE)malloc(sizeof(NODE));//循环动态分配了一个新结点
//接下来要把本次分配的新结点和头结点以及上次分配的结点串联起来
pNew->data = val;
pTail->Pnext = pNew;
pNew->Pnext = NULL;
pTail = pNew;
//这样其实是倒着生成的链表,最终把整个链表串联起来
}
return pHead;
}
//遍历链表输出
void traverse_list(PNODE pHead)
{
PNODE p = pHead->Pnext;
printf("该链表的全部有效数据为:");
while (NULL!=p)
{
printf("%d ",p->data);
p=p->Pnext;
}
printf("\n");
}
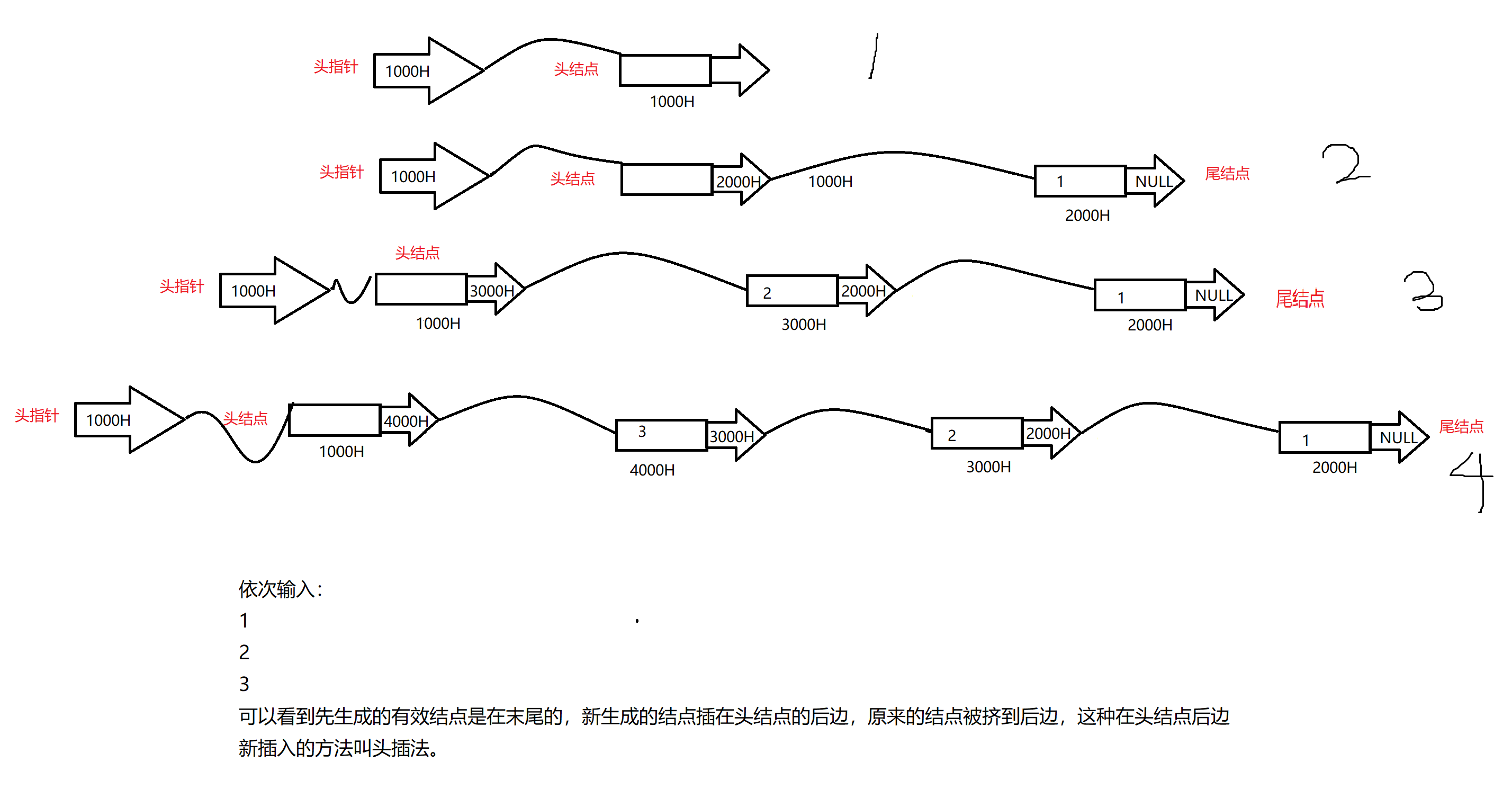
[!NOTE] 上述例子其实是尾插法实现的创建链表, 我把它理解为是按照从头到尾顺序添加结点,永远把新添加的结点的指针域置为空,这样也好理解。
常用的其他简单方法还有头插法。(下面介绍)
//头插法实现
#include <stdio.h>
#include <malloc.h>
typedef struct NODE
{
int data;
struct NODE* next;
}NODE, * PNODE;
PNODE creat_List(void);
void traverse_list(PNODE pHead);
int main()
{
PNODE pHead = NULL;
pHead = creat_List();
traverse_list(pHead);
return 0;
}
PNODE creat_List(void)
{//头插法
PNODE pHead = NULL;
PNODE pNew;
int val;
pHead = (PNODE)malloc(sizeof(NODE));
pHead->next = NULL;
scanf_s("%d", &val);
while (val != -1)
{
pNew = (PNODE)malloc(sizeof(NODE));
pNew->data = val;
//新结点p的next指针域指向L的开始结点(pHead->next)
pNew->next = pHead->next;
//头结点的next指针域指向新结点p,使得新结点p成为新的开始结点
pHead->next = pNew;
scanf_s("%d", &val);
}
return pHead;
}
void traverse_list(PNODE pHead)
{
PNODE p = pHead->next;
printf("该链表的全部有效数据为:");
while (NULL!=p)
{
printf("%d ",p->data);
p=p->next;
}
printf("\n");
}
本文章使用limfx的vsocde插件快速发布